추천 콘텐츠
현금을 안 써도 되는 세상
지하철을 타고 출근하는 사람들, 현금을 사용하지 않고 카드만 대면 끝입니다. 신용 카드의 후불 교통 카드 기능을 사용하면 따로 충전하는 번거로움 없이 대중교통을 이용할 수 있죠. 동료들과 점심 식사 후에 송금할 일이 있다면? 내 몫의 금액을 간단하게 모바일로 보내면 끝입니다. 퇴근 후 업무 스트레스를 날려 버리기 위해 인터넷 쇼핑을 하기도 합니다. 장바구니에 넣어 뒀던 소중한 상품들도 간단히 ○○페이를 이용해 결제하면 금방입니다.
참으로 일상적인 하루죠? 하루 일과에서 구경할 수 없는 것이 하나 있는데, 무엇인지 감이 오시나요? 바로 현금입니다. 하루 동안 여러 번의 지출이 있는데도 불구하고 현금은 단 1원도 사용되지 않았습니다. 모든 것이 전자 화폐로 해결됐죠. 최근 현금을 사용한 적 있나요?
우크라이나를 위한 기부, 암호 화폐로
잠깐 우크라이나 이야기를 해볼게요. 러시아가 우크라이나를 침공한 후, 우크라이나 정부는 각국에 구호 물품을 요청했습니다. 2022년 2월 말, 우크라이나 정부는 온라인 모금 사이트를 열었는데, 암호 화폐로 기부를 받기도 했습니다. 전통적인 모금보다 암호 화폐 모금 절차가 훨씬 간단한 덕분에 전 세계에서 많이 참여했죠. 비트코인, 이더리움, 테더 등 두 달 막 지난 시점에 집계된 모금액은 6572만 달러를 넘어섰습니다. 우리 돈으로 800억 원이 넘는 돈이죠. 암호 화폐뿐만 아니라 전쟁의 참상을 NFT로 기록해서 발행하기도 했는데, 네 달 지난 시점에 77만 달러를 판매했습니다. 우리의 하루에서도 우크라이나 전쟁에서도 현금의 모습을 찾아보긴 힘듭니다. 실생활에서 점점 현금의 모습은 사라져 가고 있는 듯해요.
ⓒ일러스트: 안준석/마부작침
현금을 안 써도 되는 세상
현금 이용은 계속 줄고 있습니다. 선진국을 중심으로 현금 이용이 지속적으로 감소하고 있죠. 스웨덴, 영국은 2000년대 이후부터 신용 카드와 모바일 중심으로 소비가 이뤄지면서 현금 없는 사회로 빠르게 진전했습니다. 스웨덴은 아예 손등에 심은 마이크로칩으로 결제를 할 정도니까요. 주요 국가들의 현금 결제 비중을 나타낸 그래프[1]입니다. 2020년 기준 스웨덴의 현금 결제 비중은 9.0퍼센트에 불과하죠. 2018년 기준 우리나라의 현금 결제 비중도 19.8퍼센트로 상당히 낮은 편에 속합니다.
현금 이용은 계속 줄고 있습니다. 선진국을 중심으로 현금 이용이 지속적으로 감소하고 있죠. 스웨덴, 영국은 2000년대 이후부터 신용 카드와 모바일 중심으로 소비가 이뤄지면서 현금 없는 사회로 빠르게 진전했습니다. 스웨덴은 아예 손등에 심은 마이크로칩으로 결제를 할 정도니까요. 주요 국가들의 현금 결제 비중을 나타낸 그래프[1]입니다. 2020년 기준 스웨덴의 현금 결제 비중은 9.0퍼센트에 불과하죠. 2018년 기준 우리나라의 현금 결제 비중도 19.8퍼센트로 상당히 낮은 편에 속합니다.
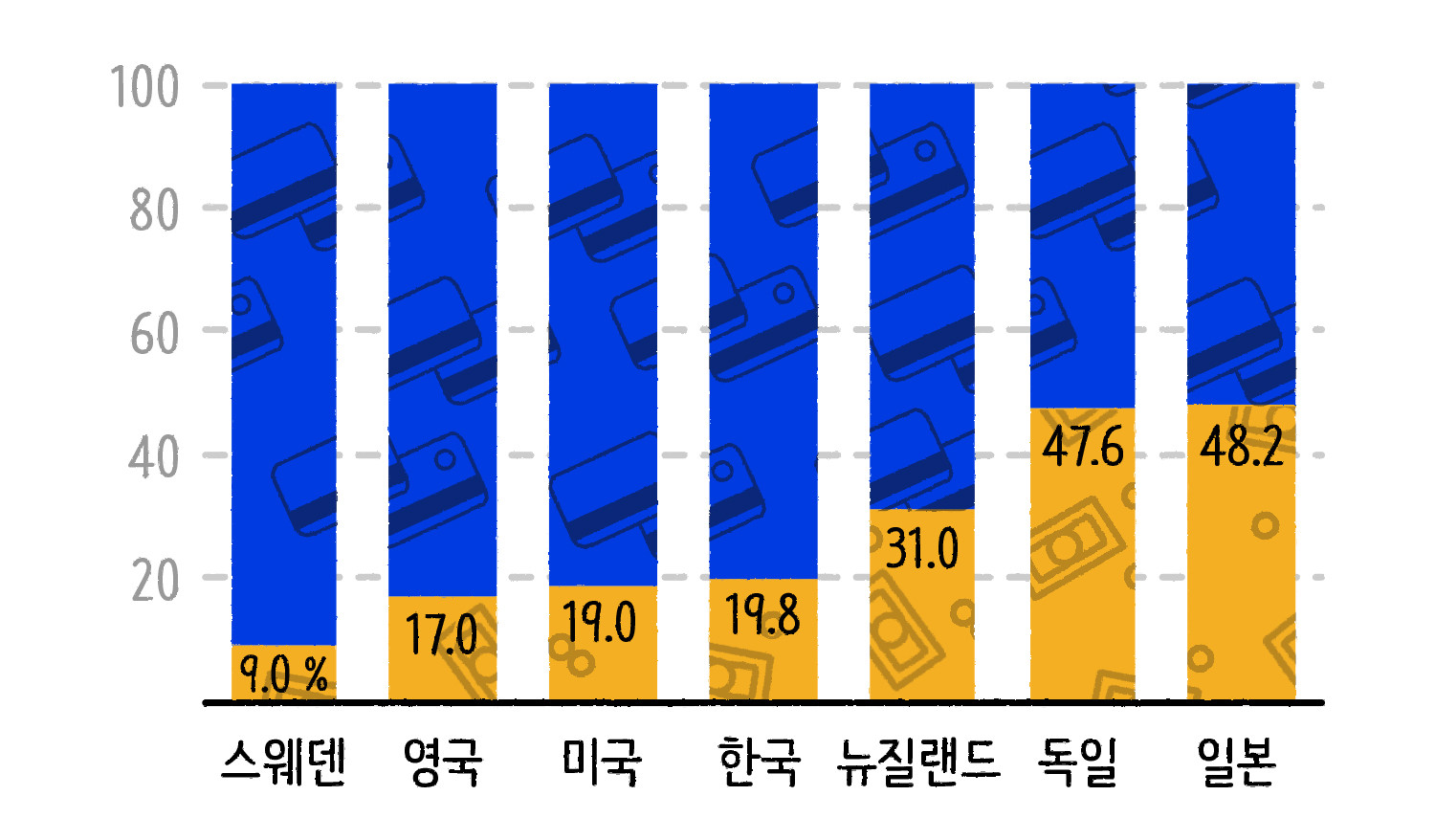
그래프 캡션 주요 국가별 현금 지급액, 단위: 퍼센트 ⓒ일러스트: 안준석/마부작침
과거에 비해 확실히 현금 이용의 편의성이 줄어들었습니다. 접근성도 떨어졌죠. ATM기와 은행 지점 수도 감소했습니다. 한국은행의 데이터33로 인구 10만 명 대비 ATM 설치 건수를 분석하면, 2013년 수치가 246.4대로 가장 높습니다. 2020년에는 226.9대로 2013년 대비 7.9퍼센트나 감소했죠. 은행 지점 수도 비슷한 흐름입니다. 인구 10만 명 대비 전국상업 은행 점포 수를 살펴보면 2012년 15.6개로 최고점을 찍고 감소합니다. 2020년엔 12.7개로 2012년 대비 18.4퍼센트나 줄어들었어요.
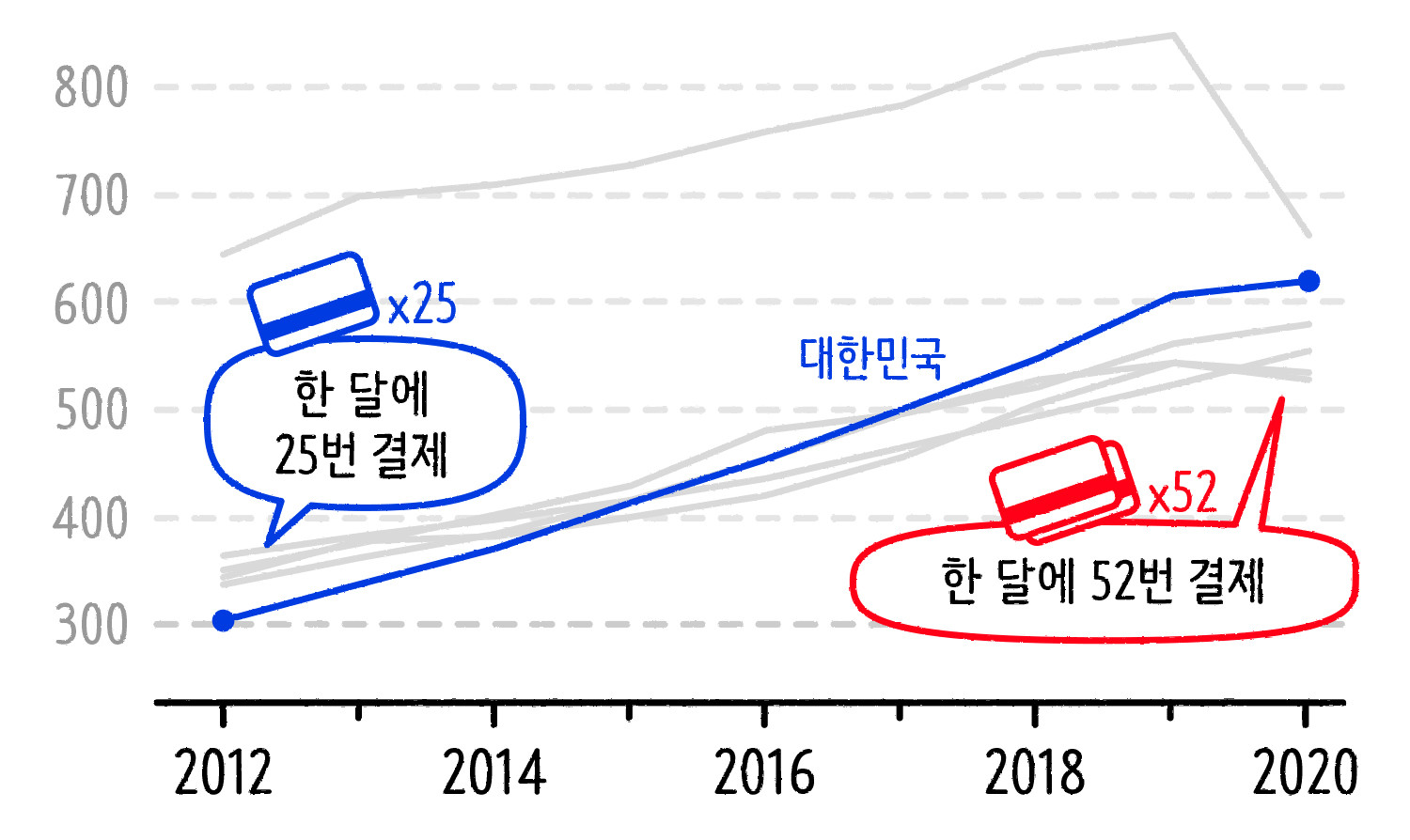
주요 국가별 일인당 연간 카드 결제 현황 ⓒ일러스트: 안준석/마부작침
위 그래프는 국제결제은행 BIS 데이터[2]를 바탕으로 그린 주요 국가별 일인당 카드 결제 횟수입니다. BIS에서 주요 국가들의 중앙은행 자료를 확인할 수 있는데, 그중 연간 결제 횟수가 300회 이상인 국가만 골라서 그래프를 그렸습니다. 우리나라는 2012년 303.6회, 그러니까 하루에 0.8번, 한 달에 25번꼴로 카드를 긁었습니다. 2020년 620.7회로 싱가포르에 이어 2위를 차지했습니다. 하루에 1.7번 카드 결제가 이뤄진 거죠. 2020년은 코로나19 바이러스 확산으로 비대면 거래가 늘어난 탓에 주요 국가들의 카드 결제 횟수가 감소했습니다. 카드를 긁을 필요 없이 모바일로 결제하면 되니까요.
기술이 워낙 발전하다 보니 모든 산업 부문에서 디지털 전환이 가속화됐습니다. 네이버, 카카오 등 빅테크 기업 중심으로 새로운 지급 결제 서비스가 등장했고, 코로나19 바이러스 확산으로 비대면 거래가 확 늘어났습니다. 카카오페이, 네이버페이, 삼성페이 등 전자 화폐뿐만 아니라 비트코인, 이더리움 같은 암호 화폐도 거래에 사용되고 있죠. 앞에서 이야기한 우크라이나의 암호 화폐 모금이 놀라운 일이 아니게 된 겁니다. 어찌 보면 우리가 살아가는 이 시점은 역사적인 화폐 전환기라고 볼 수 있을지 모릅니다.
기술이 워낙 발전하다 보니 모든 산업 부문에서 디지털 전환이 가속화됐습니다. 네이버, 카카오 등 빅테크 기업 중심으로 새로운 지급 결제 서비스가 등장했고, 코로나19 바이러스 확산으로 비대면 거래가 확 늘어났습니다. 카카오페이, 네이버페이, 삼성페이 등 전자 화폐뿐만 아니라 비트코인, 이더리움 같은 암호 화폐도 거래에 사용되고 있죠. 앞에서 이야기한 우크라이나의 암호 화폐 모금이 놀라운 일이 아니게 된 겁니다. 어찌 보면 우리가 살아가는 이 시점은 역사적인 화폐 전환기라고 볼 수 있을지 모릅니다.
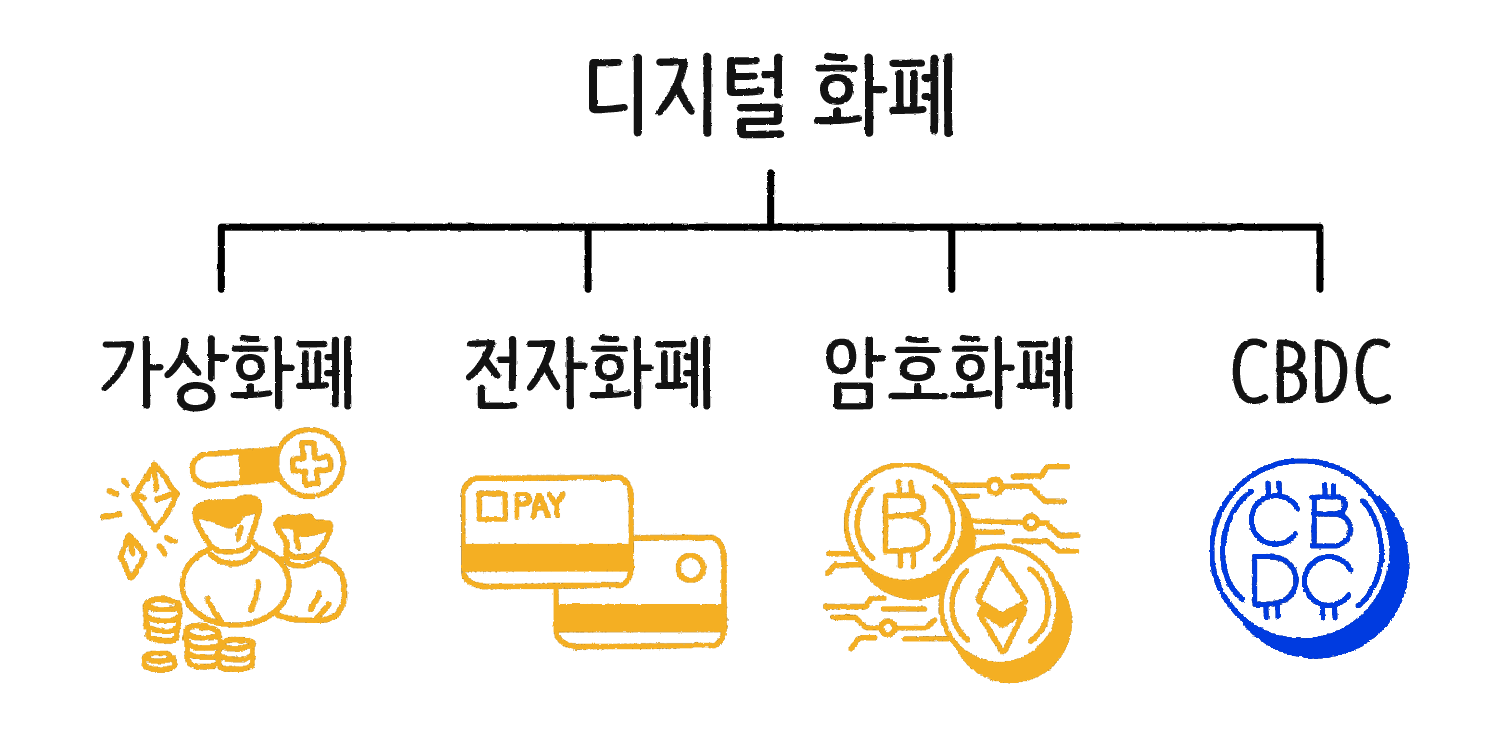
ⓒ일러스트: 안준석/마부작침
그렇다면 전자 화폐, 암호 화폐 정확하게 무엇이 다를까요? 디지털 화폐는 전자 화폐(Electronic Currency), 가상 화폐(Virtual Currency), 암호 화폐(Crypto Currency), CBDC 정도로 구분할 수 있습니다. 전자 화폐는 페이팔, 삼성페이, 카카오페이, 네이버페이처럼 금융 회사나 전자 금융업자가 발행하지만 현금과 동일한 가치로 교환할 수 있죠. 반면 가상 화폐는 발행 주체가 금융 회사나 전자 금융업자가 아니라 기업인 경우를 뜻합니다. 인터넷이나 게임에서 사용할 수 있는 캐시나 쿠폰 등이죠. 암호 화폐는 발행 주체가 정해져 있지 않습니다. 누구나 알고리즘만 풀 수 있다면 발행할 수 있습니다. 다른 디지털 화폐와 다르게 가치가 고정돼 있지 않고 수요와 공급에 따라 바뀌죠. CBDC는 정부에서 발행하는 디지털 화폐인데 좀 더 자세한 내용은 뒤에서 설명해 볼게요.
CBDC를 만드는 국가들
현금이 사라지고 디지털 경제로 급격하게 전환되는 시기, 정부와 중앙은행도 잠자코 있지만은 않습니다. 화폐라는 게 보편적인 지급 수단의 역할을 해야 하는데 정부와 중앙은행이 발행하는 현금이 예전만치 역할을 못 하고 있죠. 게다가 민간 테크 기업이 영향력을 높이고 있으니 중앙은행도 움직이기 시작한 거죠. 그래서 등장한 게 CBDC라는 새로운 화폐입니다.
생소한 단어지만 하나하나 뜯어 보면 의미를 쉽게 알 수 있습니다. CBDC를 풀어 보면 Central Bank Digital Currency인데, 말 그대로 중앙은행에서 발행하는 디지털 화폐를 뜻합니다. 2010년대 중반, 최초의 암호 화폐 비트코인이 등장하면서 중앙은행도 관련 기술에 관심을 갖기 시작했습니다. 네트워크 기술이 날로 발전하면서 분산 원장, 일종의 탈중앙화 기술이 주목받기 시작했습니다. 그리고 2015년 영국 중앙은행이 CBDC 발행의 필요성을 처음으로 세상에 알리면서 CBDC라는 새로운 개념이 등장한 거죠.
CBDC를 만드는 국가들
현금이 사라지고 디지털 경제로 급격하게 전환되는 시기, 정부와 중앙은행도 잠자코 있지만은 않습니다. 화폐라는 게 보편적인 지급 수단의 역할을 해야 하는데 정부와 중앙은행이 발행하는 현금이 예전만치 역할을 못 하고 있죠. 게다가 민간 테크 기업이 영향력을 높이고 있으니 중앙은행도 움직이기 시작한 거죠. 그래서 등장한 게 CBDC라는 새로운 화폐입니다.
생소한 단어지만 하나하나 뜯어 보면 의미를 쉽게 알 수 있습니다. CBDC를 풀어 보면 Central Bank Digital Currency인데, 말 그대로 중앙은행에서 발행하는 디지털 화폐를 뜻합니다. 2010년대 중반, 최초의 암호 화폐 비트코인이 등장하면서 중앙은행도 관련 기술에 관심을 갖기 시작했습니다. 네트워크 기술이 날로 발전하면서 분산 원장, 일종의 탈중앙화 기술이 주목받기 시작했습니다. 그리고 2015년 영국 중앙은행이 CBDC 발행의 필요성을 처음으로 세상에 알리면서 CBDC라는 새로운 개념이 등장한 거죠.
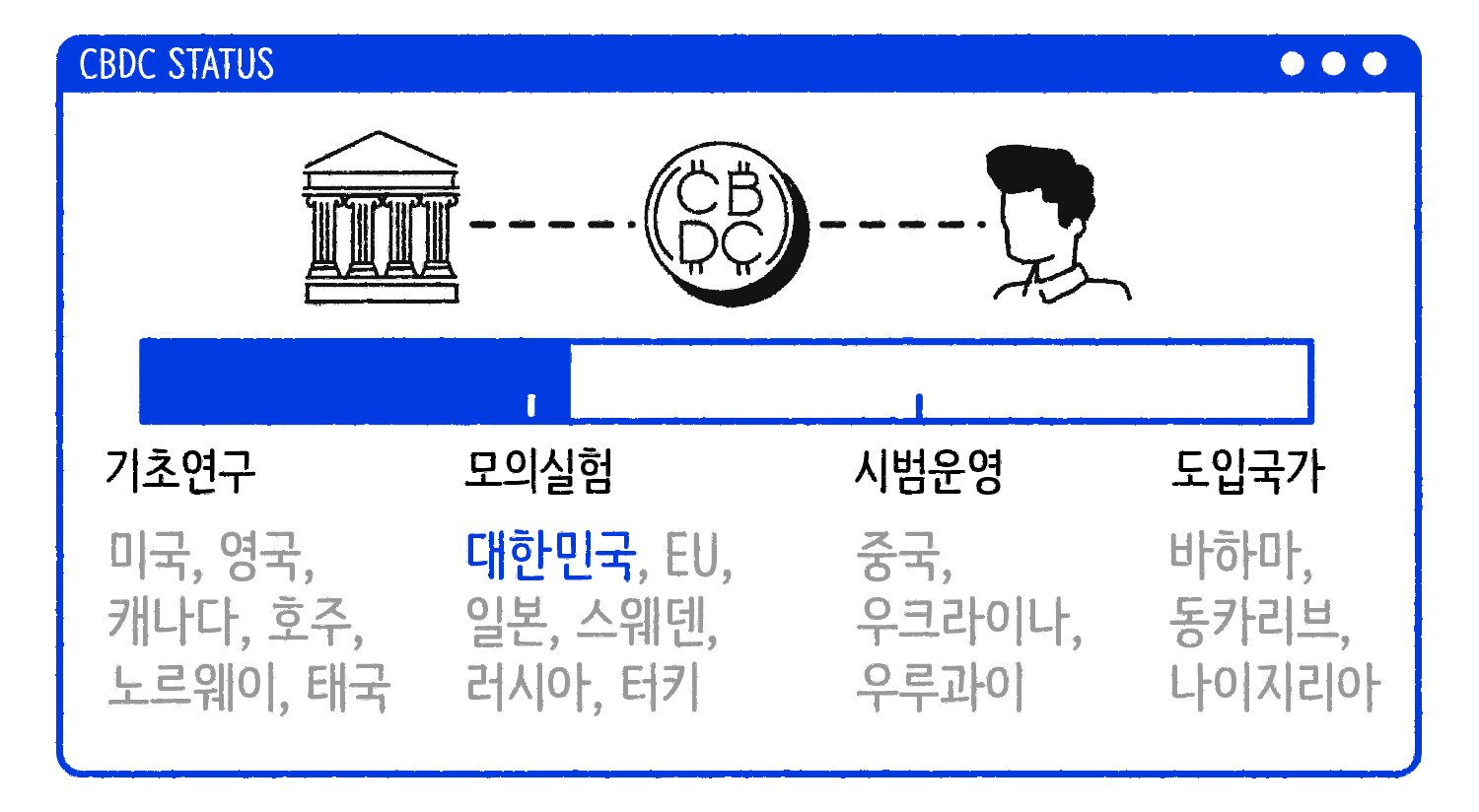
국가별 CBDC 도입 현황 ⓒ일러스트: 안준석/마부작침
중남미와 아프리카 지역의 일부 신흥 국가는 이미 CBDC를 도입하기도 했습니다. 바하마는 2020년 10월에, 동카리브 국가기구와 나이지리아는 2021년에 CBDC를 도입해서 파일럿 실험을 했습니다. 중국과 우루과이, 우크라이나는 시범적으로 CBDC를 운영하고 우리나라도 관련 실험을 진행했습니다. 카카오가 한국은행의 디지털 화폐 시범 사업자로 선정되면서 2021년부터 모의실험을 진행했습니다. 2022년 기준 모의실험에 들어간 국가는 우리나라를 포함해 6개 정도입니다.
주목할 만한 건 중국의 CBDC입니다. 중국은 주요국 중에 디지털 화폐 도입 가능성이 가장 큰 국가로 거론됩니다. 2022년 베이징 동계 올림픽에서 외국인을 대상으로 디지털 위안화 e-CNY를 개방하기도 했어요. 베이징, 상하이 등 열한 개 도시에 시범 보급하면서 2021년 말 기준으로 누적 거래액이 875억 위안을 기록했습니다. 알리바바의 기업 상장을 무력화한 이면에도 디지털 위안화가 있다는 얘기가 들렸을 정도로 중국은 CBDC 도입에 진심을 보였습니다.
왜 이렇게까지 한 걸까요? 바로 디지털 화폐에서 미국 달러가 되기 위해서죠. 미국 달러는 현실 세계에서 기축 통화로서 지위를 갖고 있습니다. 그만큼 세계 경제에 미치는 영향력도 대단하죠. 미국의 한마디로 전 세계 경제 방향이 바뀌기도 할 정도니까 말입니다. 중국은 미국의 상대국이자 G2로 불리기도 하지만 달러 패권을 깨뜨리는 건 쉽지 않습니다. 현실 세상에서 미국의 달러 패권을 흔드는 게 힘들다면, 디지털에서 기축 통화가 되겠다는 거죠. 디지털 세상의 통화 패권을 쥐겠다는 중국의 욕망이 담겨 있는 겁니다. 중국이 CBDC 개발에 속도를 내자 잠잠했던 미국도 움직이기 시작했습니다. 2022년 3월, 바이든 대통령은 디지털 달러를 공식적으로 추진한다고 밝혔습니다.
현금 없는 사회 Good or Bad?
국가에서 준비하는 CBDC, 민간에서 내놓는 디지털 화폐까지. 현금 없는 사회는 이미 도래한 것 같죠. 현금 없는 사회가 되면 무엇이 달라질까요? 스마트폰만 있으면 일사천리로 구매, 금융 거래까지 다 할 수 있으니까 일단 편리합니다. 현금으로 주고받던 때보다 시간은 단축되고, 현금을 관리하고 저장하기 위해 신경 쓸 일이 없습니다.
그런 이야기도 들어 봤을 겁니다. 10원 동전 하나 만드는 데 10원보다 훨씬 큰돈이 들어간다는 이야기 말이죠. 2006년 이전까지 10원 동전 하나를 만드는 데 대략 30~40원이 들었습니다. 2006년엔 그걸 줄여 보려고 10원 동전의 금속 구성을 바꿨는데, 여전히 10원 하나에 20원에 가까운 금액이 들고 있죠. 현금 없는 세상에선 이렇게 동전, 지폐를 만드는 데 돈이 들지 않으니까 비용이 절약되는 장점도 있습니다.
또 하나의 장점은 전자 기록으로 투명성이 확대된다는 점입니다. 내가 가지고 있는 1000원짜리 지폐 한 장이 어디서 왔는지 아무도 모릅니다. 물론 직전의 거래까지는 기억에 남아 있을 수 있지만 지폐 한 장, 동전 하나가 나에게 들어오기까지 거래 내역은 아무도 알 수 없죠. 디지털로 거래가 이뤄지는 현금 없는 사회에선 현금의 익명성이 사라질 수 있어요. 모든 거래의 흔적이 디지털 기록으로 남을 테니까요. 자금 세탁 같은 범죄를 예방할 수 있는 거죠.
물론 긍정적인 측면만 있는 건 아닙니다. 일단 모든 게 전자 시스템으로 이뤄지다 보니 시스템이 다운될 경우 답이 없습니다. 결제 자체가 이뤄지지 않을 수 있거든요. 해외에서 비슷한 상황이 발생하기도 했어요. 아까 동카리브가 이미 CBDC를 도입했다고 했죠. 동카리브의 디지털 화폐DCash는 2022년 1월 기술적인 이슈로 몇 주간 오프라인 상태였습니다. 당연히 디지털 화폐를 통한 거래는 이뤄지지 못했죠.
또 모든 게 전자로 기록된다는 건, 다르게 말하면 나의 모든 경제 활동을 정부가 속속들이 알 수 있다는 겁니다. 디지털 화폐를 이용하는 사람의 모든 거래 기록이 전자적으로 저장된다는 거니까요. 내가 어디서 뭘 구매했는지, 또 얼마나 구매했는지, 모든 걸 정부는 알 수 있다는 거죠. 사생활 침해 이슈도 뜨거운 감자입니다. 그런 점에서 중국이 CBDC에 가장 유리한 국가라고 분석하기도 합니다. 다른 민주 국가에선 사생활을 침해하지 않도록 법적 제도가 만들어져야 하지만 국가의 권력이 센 중국은 상대적으로 접근하기 쉬울 수 있다는 거죠.
디지털 화폐가 통용될 경우, 디지털 약자가 경제 활동에서 소외될 가능성이 생긴다는 것도 고려해야 할 부분입니다. 고령층과 장애인 등은 현금 의존도가 상대적으로 다른 계층보다 높은데, 현금 없는 사회가 돼버리면 현금 결제가 근본적으로 어려워질 테니 큰 불편을 겪을 수 있거든요. 현금 없는 사회에 가장 가까이 있는 스웨덴에서 설문 조사를 하니 기본 결제 서비스에 대한 고령층의 만족도가 낮게 나오기도 했어요.
현금 없는 세상에 대해 데이터로 살펴봤습니다. 화폐의 미래는 어떨까요? 현금 없는 세상은 거스를 수 없는 미래일까요? 디지털 화폐가 결국 현금을 대체하게 될까요? 아니면 현금을 보완하는 데 그칠까요?
챗GPT의 월간 사용자 수가 1억 명을 돌파하는 데 걸린 시간은 단 2개월. 인스타그램이 1억 명을 달성하는 데 걸린 시간은 2년 6개월입니다. 유튜브는 2년 10개월 걸렸고요. 구글은 8년이 걸렸다고 합니다. 마이크로소프는 챗GPT를 심은 검색 엔진 빙을 발표했고, 이에 뒤질세라 구글도 바드라는 챗봇을 공개했습니다. 이런 상황을 보면 우리 주변의 기술이 정말 미친 듯한 속도로 발전하고 있는 것 같습니다. 하루가 다르게 기술이 진화한다는 느낌이 드는 오늘날, 정말 그럴까요?
챗GPT는 알까
거두절미하고 챗GPT에게 물었습니다. 기술은 점점 더 빠르게 발전하고 있냐고 말이죠. 질문을 던진 챗GPT는 웹 액세스 기능을 추가한 web-챗GPT 버전입니다. 비교적 가까운 시일 내 인터넷에 올라온 정보까지 접근 가능한 챗GPT이니 더 정확한 정보를 얻을 수 있겠다는 기대였습니다.
챗GPT가 바로 대답해 줬습니다. “네, 기술은 과거보다 빠르게 발전하고 있습니다.” 챗GPT가 근거로 들었던 건 컴퓨터의 성능 발전, 데이터 양의 증가, 데이터 스토리지의 개선 정도입니다. 지금부터 챗GPT가 이야기한 데이터를 중심으로 기술이 얼마나 발전해 왔는지 검증해 봅니다.
먼저 데이터의 양부터 살펴봅니다. 인류가 여태껏 생산한 모든 데이터를 합치면 얼마나 될 것 같나요? 2018년 기준으로 인간이 만든 데이터의 용량은 33제타바이트(ZB) 정도입니다. 1제타바이트는 1,000,000,000,000,000,000,000바이트로 0이 21개나 붙어 있는 단위입니다. 익숙한 단위로 환산하면 조, 경, 다음 단위를 사용해서 10해라고 표현할 수 있죠. 호주국립대학교의 천문학자들이 현대 망원경으로 볼 수 있는 별을 추정한 게 70제타 개 정도입니다. 얼마나 대단한 양인지 알겠죠?
주목할 만한 건 중국의 CBDC입니다. 중국은 주요국 중에 디지털 화폐 도입 가능성이 가장 큰 국가로 거론됩니다. 2022년 베이징 동계 올림픽에서 외국인을 대상으로 디지털 위안화 e-CNY를 개방하기도 했어요. 베이징, 상하이 등 열한 개 도시에 시범 보급하면서 2021년 말 기준으로 누적 거래액이 875억 위안을 기록했습니다. 알리바바의 기업 상장을 무력화한 이면에도 디지털 위안화가 있다는 얘기가 들렸을 정도로 중국은 CBDC 도입에 진심을 보였습니다.
왜 이렇게까지 한 걸까요? 바로 디지털 화폐에서 미국 달러가 되기 위해서죠. 미국 달러는 현실 세계에서 기축 통화로서 지위를 갖고 있습니다. 그만큼 세계 경제에 미치는 영향력도 대단하죠. 미국의 한마디로 전 세계 경제 방향이 바뀌기도 할 정도니까 말입니다. 중국은 미국의 상대국이자 G2로 불리기도 하지만 달러 패권을 깨뜨리는 건 쉽지 않습니다. 현실 세상에서 미국의 달러 패권을 흔드는 게 힘들다면, 디지털에서 기축 통화가 되겠다는 거죠. 디지털 세상의 통화 패권을 쥐겠다는 중국의 욕망이 담겨 있는 겁니다. 중국이 CBDC 개발에 속도를 내자 잠잠했던 미국도 움직이기 시작했습니다. 2022년 3월, 바이든 대통령은 디지털 달러를 공식적으로 추진한다고 밝혔습니다.
현금 없는 사회 Good or Bad?
국가에서 준비하는 CBDC, 민간에서 내놓는 디지털 화폐까지. 현금 없는 사회는 이미 도래한 것 같죠. 현금 없는 사회가 되면 무엇이 달라질까요? 스마트폰만 있으면 일사천리로 구매, 금융 거래까지 다 할 수 있으니까 일단 편리합니다. 현금으로 주고받던 때보다 시간은 단축되고, 현금을 관리하고 저장하기 위해 신경 쓸 일이 없습니다.
그런 이야기도 들어 봤을 겁니다. 10원 동전 하나 만드는 데 10원보다 훨씬 큰돈이 들어간다는 이야기 말이죠. 2006년 이전까지 10원 동전 하나를 만드는 데 대략 30~40원이 들었습니다. 2006년엔 그걸 줄여 보려고 10원 동전의 금속 구성을 바꿨는데, 여전히 10원 하나에 20원에 가까운 금액이 들고 있죠. 현금 없는 세상에선 이렇게 동전, 지폐를 만드는 데 돈이 들지 않으니까 비용이 절약되는 장점도 있습니다.
또 하나의 장점은 전자 기록으로 투명성이 확대된다는 점입니다. 내가 가지고 있는 1000원짜리 지폐 한 장이 어디서 왔는지 아무도 모릅니다. 물론 직전의 거래까지는 기억에 남아 있을 수 있지만 지폐 한 장, 동전 하나가 나에게 들어오기까지 거래 내역은 아무도 알 수 없죠. 디지털로 거래가 이뤄지는 현금 없는 사회에선 현금의 익명성이 사라질 수 있어요. 모든 거래의 흔적이 디지털 기록으로 남을 테니까요. 자금 세탁 같은 범죄를 예방할 수 있는 거죠.
물론 긍정적인 측면만 있는 건 아닙니다. 일단 모든 게 전자 시스템으로 이뤄지다 보니 시스템이 다운될 경우 답이 없습니다. 결제 자체가 이뤄지지 않을 수 있거든요. 해외에서 비슷한 상황이 발생하기도 했어요. 아까 동카리브가 이미 CBDC를 도입했다고 했죠. 동카리브의 디지털 화폐DCash는 2022년 1월 기술적인 이슈로 몇 주간 오프라인 상태였습니다. 당연히 디지털 화폐를 통한 거래는 이뤄지지 못했죠.
또 모든 게 전자로 기록된다는 건, 다르게 말하면 나의 모든 경제 활동을 정부가 속속들이 알 수 있다는 겁니다. 디지털 화폐를 이용하는 사람의 모든 거래 기록이 전자적으로 저장된다는 거니까요. 내가 어디서 뭘 구매했는지, 또 얼마나 구매했는지, 모든 걸 정부는 알 수 있다는 거죠. 사생활 침해 이슈도 뜨거운 감자입니다. 그런 점에서 중국이 CBDC에 가장 유리한 국가라고 분석하기도 합니다. 다른 민주 국가에선 사생활을 침해하지 않도록 법적 제도가 만들어져야 하지만 국가의 권력이 센 중국은 상대적으로 접근하기 쉬울 수 있다는 거죠.
디지털 화폐가 통용될 경우, 디지털 약자가 경제 활동에서 소외될 가능성이 생긴다는 것도 고려해야 할 부분입니다. 고령층과 장애인 등은 현금 의존도가 상대적으로 다른 계층보다 높은데, 현금 없는 사회가 돼버리면 현금 결제가 근본적으로 어려워질 테니 큰 불편을 겪을 수 있거든요. 현금 없는 사회에 가장 가까이 있는 스웨덴에서 설문 조사를 하니 기본 결제 서비스에 대한 고령층의 만족도가 낮게 나오기도 했어요.
현금 없는 세상에 대해 데이터로 살펴봤습니다. 화폐의 미래는 어떨까요? 현금 없는 세상은 거스를 수 없는 미래일까요? 디지털 화폐가 결국 현금을 대체하게 될까요? 아니면 현금을 보완하는 데 그칠까요?
파괴적인 혁신, 아직 가능할까
챗GPT의 월간 사용자 수가 1억 명을 돌파하는 데 걸린 시간은 단 2개월. 인스타그램이 1억 명을 달성하는 데 걸린 시간은 2년 6개월입니다. 유튜브는 2년 10개월 걸렸고요. 구글은 8년이 걸렸다고 합니다. 마이크로소프는 챗GPT를 심은 검색 엔진 빙을 발표했고, 이에 뒤질세라 구글도 바드라는 챗봇을 공개했습니다. 이런 상황을 보면 우리 주변의 기술이 정말 미친 듯한 속도로 발전하고 있는 것 같습니다. 하루가 다르게 기술이 진화한다는 느낌이 드는 오늘날, 정말 그럴까요?
챗GPT는 알까
거두절미하고 챗GPT에게 물었습니다. 기술은 점점 더 빠르게 발전하고 있냐고 말이죠. 질문을 던진 챗GPT는 웹 액세스 기능을 추가한 web-챗GPT 버전입니다. 비교적 가까운 시일 내 인터넷에 올라온 정보까지 접근 가능한 챗GPT이니 더 정확한 정보를 얻을 수 있겠다는 기대였습니다.
챗GPT가 바로 대답해 줬습니다. “네, 기술은 과거보다 빠르게 발전하고 있습니다.” 챗GPT가 근거로 들었던 건 컴퓨터의 성능 발전, 데이터 양의 증가, 데이터 스토리지의 개선 정도입니다. 지금부터 챗GPT가 이야기한 데이터를 중심으로 기술이 얼마나 발전해 왔는지 검증해 봅니다.
먼저 데이터의 양부터 살펴봅니다. 인류가 여태껏 생산한 모든 데이터를 합치면 얼마나 될 것 같나요? 2018년 기준으로 인간이 만든 데이터의 용량은 33제타바이트(ZB) 정도입니다. 1제타바이트는 1,000,000,000,000,000,000,000바이트로 0이 21개나 붙어 있는 단위입니다. 익숙한 단위로 환산하면 조, 경, 다음 단위를 사용해서 10해라고 표현할 수 있죠. 호주국립대학교의 천문학자들이 현대 망원경으로 볼 수 있는 별을 추정한 게 70제타 개 정도입니다. 얼마나 대단한 양인지 알겠죠?

데이터 용량 단위 ⓒ일러스트: 안준석/마부작침
인간이 생산하는 데이터의 용량은 2025년 최대 181제타바이트까지 커질 것으로 예측됩니다. 2030년엔 해마다 생산하는 데이터가 1요타바이트(YB), 즉 10의 24제곱 바이트에 이를 것이라는 전망도 나오고 있죠. 2022년 11월 18일, 국제단위를 결정하고 관리하는 국제도량형총회는 가까운 미래에 10의 24제곱보다 훨씬 큰 규모의 수치 정보를 표현해야 하는 상황이 올 거라는 판단을 내렸습니다. 10의 27제곱과 10의 30제곱을 나타내는 새로운 단위를 만들기까지 했습니다. 10의 27제곱은 론나(R), 10의 30제곱은 퀘타(Q)라는 이름이 붙었습니다.
론나라는 단위가 얼마나 큰지 예를 들어 봅니다. 우리가 관측할 수 있는 우주의 크기는 지구를 중심으로 약 465억 광년 정도입니다. 465억 광년이 어느 정도냐. 빛의 속력은 1초에 2억 9979만 2458미터를 이동할 수 있는데, 이 속력은 물질 혹은 에너지가 가질 수 있는 최대 속력입니다. 이 속도로 465억 년 동안 가야 하는 거리가 바로 465억 광년인 겁니다. 지름으로 보면 930억 광년인 건데 이걸 미터로 표현하면 8.8×10의 26제곱미터로 표현할 수 있어요. 론나 단위를 사용하면 0.88론나미터(Rm). 천문학적인 규모도 론나 단위를 사용하면 1이 되질 않습니다.
아이러니하게도 단위 상승을 이끄는 건 거대한 우주가 아닌 아주 작은 반도체 칩입니다. 그 안에서 이뤄지는 컴퓨터와 데이터 과학입니다. 데이터의 양은 과거보다 훨씬 빠른 속도로 늘어나고 있습니다. 그리고 그걸 바탕으로 학습하는, 바로 챗GPT 같은 AI 모델들이 막대한 데이터를 양분 삼아 엄청난 속도로 성장하고 있어요.
데이터 처리 능력의 가속 발전
단순히 데이터의 양만 늘어나는 게 아니라 그걸 처리하고 연산하는 컴퓨터의 능력도 좋아지고 있습니다. 무어의 법칙을 들어본 적 있을 겁니다. 집적 회로의 트랜지스터 수가 2년마다 두 배로 증가한다는 법칙을 말하죠. 인텔의 공동 창립자 고든 무어의 이름을 따서 만들어졌습니다.
집적 회로는 전기 회로와 반도체를 모아 하나의 칩으로 구현한 걸 의미합니다. 마치 압축 파일처럼 칩 하나에 욱여넣는 거죠. 집적 회로에 주로 들어가는 반도체 소자가 트랜지스터인데, 트랜지스터가 많으면 많을수록 전자 기기의 성능이 좋아진다고 볼 수 있습니다. 컴퓨터의 두뇌 격인 CPU에 이 집적 회로가 사용되면서 컴퓨터의 크기는 줄어들고 성능은 고도화되는 혁명 같은 발전이 이뤄진 거죠.
론나라는 단위가 얼마나 큰지 예를 들어 봅니다. 우리가 관측할 수 있는 우주의 크기는 지구를 중심으로 약 465억 광년 정도입니다. 465억 광년이 어느 정도냐. 빛의 속력은 1초에 2억 9979만 2458미터를 이동할 수 있는데, 이 속력은 물질 혹은 에너지가 가질 수 있는 최대 속력입니다. 이 속도로 465억 년 동안 가야 하는 거리가 바로 465억 광년인 겁니다. 지름으로 보면 930억 광년인 건데 이걸 미터로 표현하면 8.8×10의 26제곱미터로 표현할 수 있어요. 론나 단위를 사용하면 0.88론나미터(Rm). 천문학적인 규모도 론나 단위를 사용하면 1이 되질 않습니다.
아이러니하게도 단위 상승을 이끄는 건 거대한 우주가 아닌 아주 작은 반도체 칩입니다. 그 안에서 이뤄지는 컴퓨터와 데이터 과학입니다. 데이터의 양은 과거보다 훨씬 빠른 속도로 늘어나고 있습니다. 그리고 그걸 바탕으로 학습하는, 바로 챗GPT 같은 AI 모델들이 막대한 데이터를 양분 삼아 엄청난 속도로 성장하고 있어요.
데이터 처리 능력의 가속 발전
단순히 데이터의 양만 늘어나는 게 아니라 그걸 처리하고 연산하는 컴퓨터의 능력도 좋아지고 있습니다. 무어의 법칙을 들어본 적 있을 겁니다. 집적 회로의 트랜지스터 수가 2년마다 두 배로 증가한다는 법칙을 말하죠. 인텔의 공동 창립자 고든 무어의 이름을 따서 만들어졌습니다.
집적 회로는 전기 회로와 반도체를 모아 하나의 칩으로 구현한 걸 의미합니다. 마치 압축 파일처럼 칩 하나에 욱여넣는 거죠. 집적 회로에 주로 들어가는 반도체 소자가 트랜지스터인데, 트랜지스터가 많으면 많을수록 전자 기기의 성능이 좋아진다고 볼 수 있습니다. 컴퓨터의 두뇌 격인 CPU에 이 집적 회로가 사용되면서 컴퓨터의 크기는 줄어들고 성능은 고도화되는 혁명 같은 발전이 이뤄진 거죠.
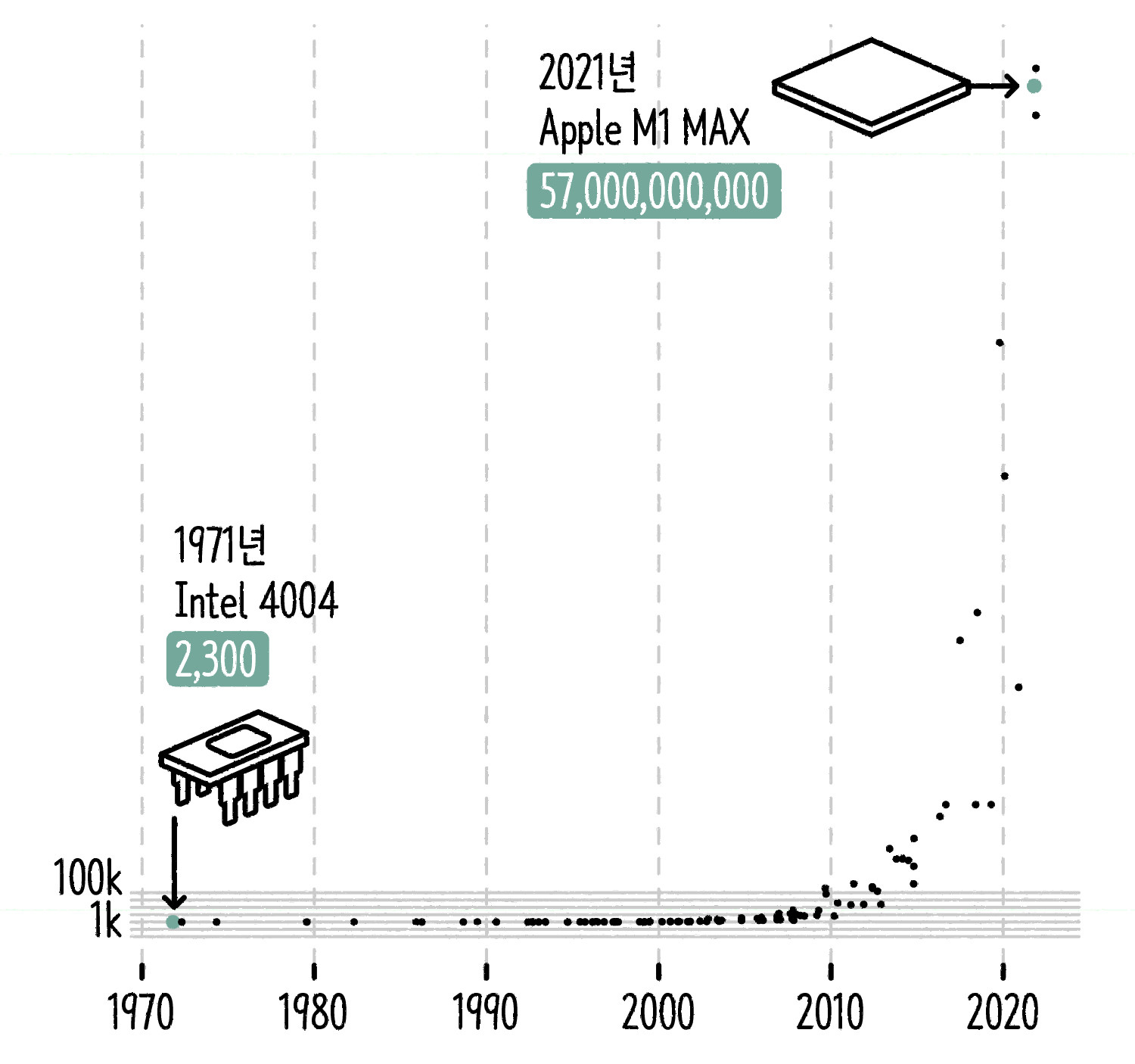
1971~2021년 주요 집적 회로의 트랜지스터 수 ⓒ일러스트: 안준석/마부작침
무어의 법칙은 위의 그래프[4]와 같이 표시할 수 있습니다. 1971년부터 2021년까지 50년간 주요 집적 회로의 트랜지스터 수를 나타낸 겁니다. 트랜지스터 수는 말 그대로 기하급수적으로 늘었습니다. 1971년 세계 최초 CPU인 Intel 4004에 사용된 트랜지스터는 2300개 정도였습니다. 그로부터 50년 뒤, 2021년 애플이 공개한 M1 Max 칩에 사용된 트랜지스터는 무려 570억 개입니다. 50년 사이 트랜지스터 개수는 2478만 배 이상 뛰어올랐어요.
데이터도 많아지고, 이를 가지고 연산하는 컴퓨터의 성능도 기하급수적으로 좋아졌습니다. 이를 활용하는 인공지능역시 엄청난 발전 속도를 자랑하고 있습니다. 스탠퍼드대학교에서 발간한 AI 보고서를 보면 2010년 이후 인공지능의 성능 향상 속도는 무어의 법칙보다 일곱 배나 빠릅니다. 집적 회로 성능이 2년에 두 배씩 향상한다면 인공지능 성능은 3.4개월에 두 배씩 좋아지고 있는 거죠.
성능이 좋아지면서 비용은 물론 학습에 걸리는 시간도 점점 줄어들고 있습니다. 2018년 이후 인공지능이 이미지를 분류하기 위해 훈련하는 데 드는 비용은 최대 63.6퍼센트 줄었습니다. 거기에 훈련 시간은 94.4퍼센트 감소했죠. 비용도 줄고 훈련 시간도 단축되면서 AI 기술은 점점 고도화되고 있습니다. 발전한 AI 기술을 활용하는 연구도 많아졌습니다. 구글의 딥마인드가 공개한 단백질 구조 예측 AI 툴을 활용한 연구팀은 이전 10년의 연구 결과보다 더 많은 단백질 구조를 단 3개월 만에 밝혀낼 정도입니다.
기술 혁신은 과거보다 둔화했다?
“어디를 둘러봐도 아이디어를 찾기가 점점 어려워지고 있습니다.”
빠른 기술 발전 속도를 체감할 수 있는 시대에 무슨 뚱딴지같은 소리야 하겠지만, 이는 MIT와 스탠퍼드대학교 연구진이 내놓은 결론입니다. 미국의 연구 생산성은 매년 5.3퍼센트씩 감소하고 있습니다. 13년이면 절반으로 떨어지죠. 이를 상쇄하기 위해선 13년마다 연구에 투입되는 자원을 두 배로 늘려야 합니다. 인력은 물론 예산도 말입니다. 이를 유지하지 못하면 연구 생산성은 떨어질 수밖에 없겠죠.
앞에서 이야기했던 무어의 법칙을 계속해서 유지하려면 1970년대 초 필요했던 연구원보다 18배 많은 인력이 필요한 상황입니다. 이전엔 집적 회로의 집적도가 오를수록 원가가 절감됐지만 이제는 불가능한 상황인 거죠. 경제성 측면에서 더 이상 무어의 법칙을 유지할 수 없게 됐다는 겁니다. 2022년 엔비디아의 CEO 젠슨 황은 이렇게 말합니다. 무어의 법칙은 완전히 끝났다고요. 비슷한 비용으로 두 배의 성능 상승을 기대하는 건 옛일이라는 거죠.
데이터도 많아지고, 이를 가지고 연산하는 컴퓨터의 성능도 기하급수적으로 좋아졌습니다. 이를 활용하는 인공지능역시 엄청난 발전 속도를 자랑하고 있습니다. 스탠퍼드대학교에서 발간한 AI 보고서를 보면 2010년 이후 인공지능의 성능 향상 속도는 무어의 법칙보다 일곱 배나 빠릅니다. 집적 회로 성능이 2년에 두 배씩 향상한다면 인공지능 성능은 3.4개월에 두 배씩 좋아지고 있는 거죠.
성능이 좋아지면서 비용은 물론 학습에 걸리는 시간도 점점 줄어들고 있습니다. 2018년 이후 인공지능이 이미지를 분류하기 위해 훈련하는 데 드는 비용은 최대 63.6퍼센트 줄었습니다. 거기에 훈련 시간은 94.4퍼센트 감소했죠. 비용도 줄고 훈련 시간도 단축되면서 AI 기술은 점점 고도화되고 있습니다. 발전한 AI 기술을 활용하는 연구도 많아졌습니다. 구글의 딥마인드가 공개한 단백질 구조 예측 AI 툴을 활용한 연구팀은 이전 10년의 연구 결과보다 더 많은 단백질 구조를 단 3개월 만에 밝혀낼 정도입니다.
기술 혁신은 과거보다 둔화했다?
“어디를 둘러봐도 아이디어를 찾기가 점점 어려워지고 있습니다.”
빠른 기술 발전 속도를 체감할 수 있는 시대에 무슨 뚱딴지같은 소리야 하겠지만, 이는 MIT와 스탠퍼드대학교 연구진이 내놓은 결론입니다. 미국의 연구 생산성은 매년 5.3퍼센트씩 감소하고 있습니다. 13년이면 절반으로 떨어지죠. 이를 상쇄하기 위해선 13년마다 연구에 투입되는 자원을 두 배로 늘려야 합니다. 인력은 물론 예산도 말입니다. 이를 유지하지 못하면 연구 생산성은 떨어질 수밖에 없겠죠.
앞에서 이야기했던 무어의 법칙을 계속해서 유지하려면 1970년대 초 필요했던 연구원보다 18배 많은 인력이 필요한 상황입니다. 이전엔 집적 회로의 집적도가 오를수록 원가가 절감됐지만 이제는 불가능한 상황인 거죠. 경제성 측면에서 더 이상 무어의 법칙을 유지할 수 없게 됐다는 겁니다. 2022년 엔비디아의 CEO 젠슨 황은 이렇게 말합니다. 무어의 법칙은 완전히 끝났다고요. 비슷한 비용으로 두 배의 성능 상승을 기대하는 건 옛일이라는 거죠.
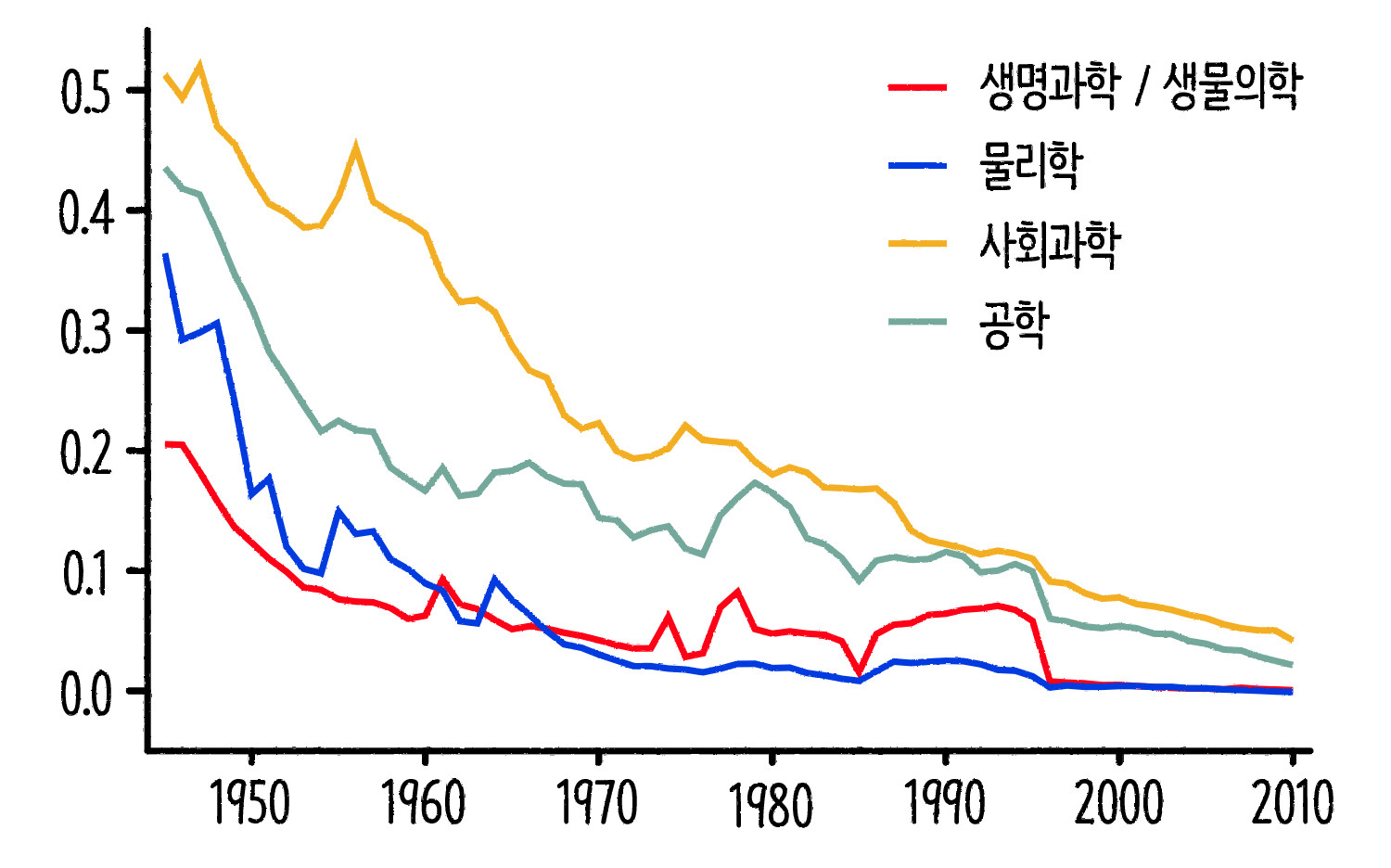
1950~2010년 논문 및 특허 분석 ⓒ일러스트: 안준석/마부작침
시간이 흐를수록 논문과 특허의 창의성이 줄어들고 있다는 연구 결과[5]도 있습니다. 연구자들은 1945~2010년의 논문 2500만 개와 1976~2010년의 특허 390만 개를 분석했습니다. 이전에 있던 연구를 인용한 정도가 높다면 기존 지식을 활용하고 발전시킨 논문으로 볼 수 있고, 그렇지 않다면 자신만의 창의적인 연구를 했다고 판단할 수 있을 겁니다. 그걸 나타낸 게 CD 지수입니다. 1에 가까울수록 선행 연구를 인용하지 않은 혁신적인 연구라는 뜻입니다. 1945년부터 2010년까지 CD 지수 흐름을 보면 감소하는 추세를 보이고 있어요.
생명 과학, 물리학, 사회 과학, 기술 과학, 분야를 가리지 않고 과거에 비해 CD 지수는 모두 감소하는 경향을 보였습니다. 1945년과 2010년을 비교했을 때, 사회 과학 분야는 91.9퍼센트 감소했고, 물리학은 100퍼센트 감소했죠. 특허도 마찬가지입니다. 화학, 컴퓨터, 제약, 전자, 기계 등 특허의 주요 분야 모두 감소하는 경향을 보였어요. 컴퓨터 및 통신 특허에서도 93.5퍼센트 감소했죠. 과거에 비해 연구과 특허의 창의성이 줄어들고 있습니다.
이런 관점에 봤을 때 챗GPT는 세상을 바꿀 파괴적인 기술일까요? 2018년 컴퓨터 과학의 노벨상이라고 불리는 튜링상을 받은 얀 레쿤은 챗GPT를 두고 훌륭한 서비스지만 혁명적이지는 않다는 평을 내렸습니다. 챗GPT는 새로운 기술이 아니라 기존에 존재하던 방법론을 공학적으로 완성도 있게 구현한 서비스라는 거죠. 사실 챗GPT를 들여다보면 구글이 발명한 트랜스포머 모델(인공신경망 모델)에 강화 학습을 적용한 서비스로 볼 수 있거든요. 물론 얀 레쿤이 오픈AI 경쟁 상대인 메타의 수석 AI 과학자라는 것은 감안할 필요가 있습니다.
지난 수십 년간 과학 연구를 평가하는 주요 지표로 사용된 건 바로 논문 인용 횟수입니다. 다른 연구 동료들이 해당 논문을 얼마나 인용했는지에 따라 연구 성과를 판단하겠다는 건데, 일각에서는 피인용 횟수가 창의적인 연구를 막는 장애물 역할을 하고 있다고 비판합니다. 과학자 입장에서 인용될 만한 논문을 쓰는 게 유리하니까 새로운 연구 분야를 개척하는 대신 인기 있는 주제로 몰리는 상황이 펼쳐진다는 거죠. 그런 인기 있는 주제가 보통 컴퓨터 과학, 인공지능 같은 소수의 주제인 거고요.
문화, 예술에서도 발견되는 혁신의 둔화
뛰어난 과학 기술을 나무에 매달린 열매라고 생각해 보면, 새로운 아이디어를 찾는 게 어려운 일이라는 건 당연할지 모릅니다. 낮은 높이에 달려 있는 열매는 이미 사람들이 따 갔을 테니까요. 이제 남은 과일은 저 높이 달려 있는 것들뿐이니. 이를 얻으려면 시간이 더 걸릴 수밖에 없겠죠.
혹은 공부할 지식의 양이 너무 많아졌다는 것도 창의적인 연구를 막는 장애물이 될 수 있습니다. 하나의 분야만 공부한다고 해도 봐야 할 정보가 많은데, 그것들을 다 보는 건 사실상 불가능하니 말입니다. 그러다 보면 가장 인기 있는 논문 위주로 볼 수밖에 없고 결국 새로운 변주를 만들어 내기 어려울 수 있겠죠. 연구뿐만 아니라 우리가 보는 콘텐츠도 비슷한 상황입니다. 넷플릭스나 유튜브 보면서 비슷한 경험을 해봤을 겁니다. 한정된 시간 내에 최고로 만족할 만한 선택을 하려면 사람들이 가장 많이 본 콘텐츠를 보는 게 안정적인 선택이 되는 거죠.
생명 과학, 물리학, 사회 과학, 기술 과학, 분야를 가리지 않고 과거에 비해 CD 지수는 모두 감소하는 경향을 보였습니다. 1945년과 2010년을 비교했을 때, 사회 과학 분야는 91.9퍼센트 감소했고, 물리학은 100퍼센트 감소했죠. 특허도 마찬가지입니다. 화학, 컴퓨터, 제약, 전자, 기계 등 특허의 주요 분야 모두 감소하는 경향을 보였어요. 컴퓨터 및 통신 특허에서도 93.5퍼센트 감소했죠. 과거에 비해 연구과 특허의 창의성이 줄어들고 있습니다.
이런 관점에 봤을 때 챗GPT는 세상을 바꿀 파괴적인 기술일까요? 2018년 컴퓨터 과학의 노벨상이라고 불리는 튜링상을 받은 얀 레쿤은 챗GPT를 두고 훌륭한 서비스지만 혁명적이지는 않다는 평을 내렸습니다. 챗GPT는 새로운 기술이 아니라 기존에 존재하던 방법론을 공학적으로 완성도 있게 구현한 서비스라는 거죠. 사실 챗GPT를 들여다보면 구글이 발명한 트랜스포머 모델(인공신경망 모델)에 강화 학습을 적용한 서비스로 볼 수 있거든요. 물론 얀 레쿤이 오픈AI 경쟁 상대인 메타의 수석 AI 과학자라는 것은 감안할 필요가 있습니다.
지난 수십 년간 과학 연구를 평가하는 주요 지표로 사용된 건 바로 논문 인용 횟수입니다. 다른 연구 동료들이 해당 논문을 얼마나 인용했는지에 따라 연구 성과를 판단하겠다는 건데, 일각에서는 피인용 횟수가 창의적인 연구를 막는 장애물 역할을 하고 있다고 비판합니다. 과학자 입장에서 인용될 만한 논문을 쓰는 게 유리하니까 새로운 연구 분야를 개척하는 대신 인기 있는 주제로 몰리는 상황이 펼쳐진다는 거죠. 그런 인기 있는 주제가 보통 컴퓨터 과학, 인공지능 같은 소수의 주제인 거고요.
문화, 예술에서도 발견되는 혁신의 둔화
뛰어난 과학 기술을 나무에 매달린 열매라고 생각해 보면, 새로운 아이디어를 찾는 게 어려운 일이라는 건 당연할지 모릅니다. 낮은 높이에 달려 있는 열매는 이미 사람들이 따 갔을 테니까요. 이제 남은 과일은 저 높이 달려 있는 것들뿐이니. 이를 얻으려면 시간이 더 걸릴 수밖에 없겠죠.
혹은 공부할 지식의 양이 너무 많아졌다는 것도 창의적인 연구를 막는 장애물이 될 수 있습니다. 하나의 분야만 공부한다고 해도 봐야 할 정보가 많은데, 그것들을 다 보는 건 사실상 불가능하니 말입니다. 그러다 보면 가장 인기 있는 논문 위주로 볼 수밖에 없고 결국 새로운 변주를 만들어 내기 어려울 수 있겠죠. 연구뿐만 아니라 우리가 보는 콘텐츠도 비슷한 상황입니다. 넷플릭스나 유튜브 보면서 비슷한 경험을 해봤을 겁니다. 한정된 시간 내에 최고로 만족할 만한 선택을 하려면 사람들이 가장 많이 본 콘텐츠를 보는 게 안정적인 선택이 되는 거죠.
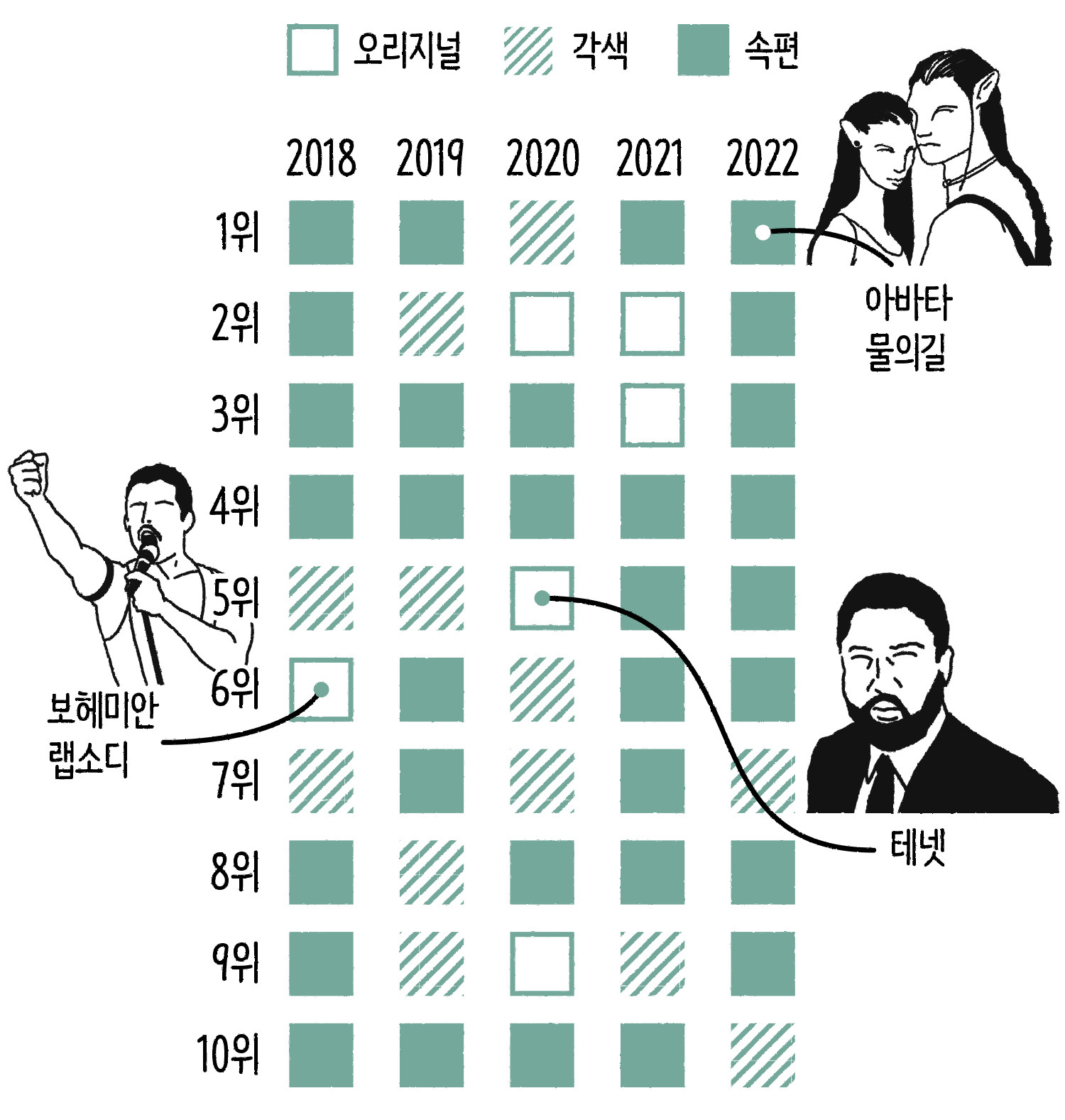
2018~2022년 전 세계 박스오피스 상위 10개 영화 ⓒ일러스트: 안준석/마부작침
넷플릭스 이야기가 나왔으니 말입니다. 대중문화, 특히 영화계에서도 비슷한 상황이 펼쳐지고 있습니다. 20세기 할리우드를 지배한 건 새로운 이야기였습니다. 하지만 지금 영화계 대세는 속편, 아니면 코믹스를 원작으로 한 히어로물이죠. 대부분 원작을 둔 영화가 만들어지고, 또 흥행도 잘 됩니다. 과거엔 새로운 캐릭터를 창조했다면 익숙한 캐릭터를 더 견고하게 만드는 데 집중하고 있는 셈입니다. 과학, 기술의 접근과 유사하지 않나요?
2018년부터 2022년까지 5년간 전 세계 박스오피스 상위 10개 영화[6]를 모아서 분류해 봤습니다. 속편은 색을 칠하고, 원작을 각색한 작품은 빗금으로 칠해서 구분했습니다. 새롭게 만들어 낸 오리지널 영화는 칸을 비웠는데, 결과는 어떨까요? 총 50편 중 오리지널 영화는 단 여섯 편에 불과합니다. 그마저도 〈보헤미안 랩소디〉는 프레디 머큐리의 전기 영화고, 중국의 프로파간다 영화와 중국 전쟁 영화를 제외하면 크리스토퍼 놀란 감독의 〈테넷〉 정도만 남죠. 나머지는 속편 아니면 코믹스 원작을 뒀거나 리메이크 작품입니다.
챗GPT는 세상을 바꿀 파괴적 발견일까?
무엇이든 물어보면 대답해 주는 챗GPT부터 무엇이든 그려 달라고 하면 그려 주는 DALL-E2, 미드저니 같은 인공지능까지. 과거에는 상상하지 못한 일들이 우리 주변에서 바로 이뤄지고 있습니다. 이렇게 고도화된 인공지능은 인류가 생각하지 못한 새로운 아이디어를 뚝딱뚝딱 만들어 내는 혁명적인 기술인 걸까요? 아니면 점점 고도화되는 기술들을 조금 더 다듬은 훌륭한 서비스일까요?
반팔티라는 단어, 어떻게 들리나요? 혹시 불편함을 느껴 본 적 있나요? 아마도 없을 겁니다. ‘반팔티’에 특별히 문제가 보이진 않으니까요. 그런데 신체장애를 가진 사람들이 ‘반팔’이라는 단어를 들을 땐 어떨까요. 실제로 장애가 있는 사람들은 반팔티라는 말을 들을 때마다 상처가 된다고 합니다. ‘반팔’ 대신 ‘반소매’라고 표현하는 게 덜 차별적이겠죠.
앉은뱅이책상, 외발 자전거, 결정 장애 등 일상 속 단어 중에 차별적 표현이 담겨 있는 경우가 왕왕 있습니다. 특정 언어를 사용하는 것 자체가 누군가에게 불편함 혹은 상처를 줄 수 있다는 겁니다. 우리가 미처 인지하지 못하고 사용해 왔던 언어에 대해 이야기해 봅니다. 특히 성차별적 언어와 그 차별을 없애기 위해 등장한 성중립 언어에 집중했습니다. 질문을 던집니다. They가 3인칭 단수 대명사로 쓰인다는 사실, 알고 있나요?
성중립 언어란 무엇인가
2018년 유럽의회에서 보고서를 하나 냈습니다. 보고서의 이름은 ‘GENDER NEUTRAL LANGUAGE in the Parliament’. 유럽의회에서 유럽연합 의 법률을 만들거나 서로 의사소통을 할 때 성중립 언어를 사용하자는 취지로 만든 겁니다. 그리고 의원, 직원들에게 배포했습니다. 일종의 가이드북을 만든 거죠. 대표적인 예는 이렇습니다. 과거 EU의 법률에는 인류mankind, 인력manpower과 같은 용어를 표현할 때 남성man의 뜻이 담긴 단어를 썼는데, 앞으로는 성중립적인 용어를 사용하자는 겁니다. 이를테면 인류는 humanity로 인력은 staff로 말이죠. 이처럼 성중립 언어는 성별로 대상을 특정하지 않는 걸 의미합니다.
물론 이 보고서가 법적 구속력이 있거나 무조건 써야 한다는 강제 규정은 아닙니다. 권고 차원에서 만들어진 보고서거든요. 유럽의회가 성중립 언어를 사용해서 좀 더 공정하고 포용적인 의미를 담고, 젠더 고정 관념을 줄여 성평등을 달성해 보자는 차원에서 접근했다고 보면 됩니다. 언어에서 성에 대한 편견과 차별을 걷어 내자는 게 이 보고서의 지향점입니다.
대표적인 성중립 언어가 바로 They입니다. “남자를 지칭할 때는 He를 쓰고, 여자를 지칭할 때는 She를 쓰고, 그리고 여러 사람을 지칭할 때는 They를 쓴다”는 문법이 바뀌고 있습니다. 3인칭 복수 인칭 대명사로 쓰여 온 They가 3인칭 단수 대명사로도 쓰이고 있거든요. 성별을 모르거나 혹은 성별을 알리고 싶지 않은 개인을 가리킬 때 They라고 부르는 식으로 말이죠. 여기에 성별을 규정하지 않는 정체성인 논바이너리를 지칭할 때도 대명사 They를 사용하고 있어요.
사실 성중립 언어에 대한 논의는 꽤 오래됐습니다. 3인칭 단수로 쓰이는 They는 이미 2015년 미국언어연구회에서 올해의 단어로 뽑을 정도니까 말이죠. 《워싱턴 포스트》 역시 2015년부터 They를 단수 대명사로도 활용하고 있기도 합니다. 미국에서 가장 오래된 사전인 메리엄 웹스터 사전에도 이 용례가 올라 있기도 해요. 2019년에는 영국 가수 샘 스미스가 자신의 정체성이 논바이너리라고 커밍아웃하면서 자신을 지칭할 때 언론에서 He나 She 대신 They를 써 달라고 요청한 일도 있었습니다.
성중립으로 변하는 언어들
영어뿐만 아니라 다른 언어를 사용하는 국가에서도 성중립 언어를 사용하려는 모습을 발견할 수 있습니다. 2015년 스웨덴 학술원은 남성과 여성을 가리지 않는 성중립 인칭 대명사를 공식 국어사전에 포함하기도 했습니다. 스웨덴어로 남성을 가리킬 땐 Han을 쓰고, 여성은 Hon을 쓰는데, 성별을 밝히지 않거나 확인되지 않을 때, 혹은 성전환 수술을 한 사람들을 지칭할 때 사용할 대명사로 Hen을 포함한 겁니다.
스웨덴에선 일찍이 1960년대부터 남성 대명사 Han을 포괄적으로 사용하는 것에 대한 비판이 있었습니다. 2010년대 들어서면서 성평등과 성중립을 위한 노력으로 성중립 대명사인 Hen이 일상생활에서 많이 사용되기 시작했습니다. 관공서뿐만 아니라 법원 판결문에도 Hen이 등장했죠. 마지막으로 스웨덴 학술원이 2015년에 공식적으로 인정을 해준 셈입니다.
독일과 프랑스에서도 비슷한 움직임이 있습니다. 그런데 영어와 스웨덴어는 상황이 조금은 다릅니다. 사실 영어, 스웨덴어는 상대적으로 성중립 언어를 적용하는 게 쉽거든요. 왜냐하면 영어와 스웨덴어는 성별이 구분된 단어가 인칭 대명사와 일반 명사 정도로 많지 않습니다. 하지만 독일어과 프랑스어는 문법 안에 성별이 들어 있는지라 상대적으로 고쳐 나가기 힘든 거죠.
예를 들면 이런 식입니다. 프랑스어는 일반적으로 남성형 명사에 e를 붙여서 여성형 명사로 만듭니다. 남성인 친구를 뜻하는 단어는 ami인데, 여성인 친구는 amie 이렇게 쓰는 거죠. 그런데 복수형으로 만들 땐 남성형 명사가 우선되는 법칙이 있습니다.
2018년부터 2022년까지 5년간 전 세계 박스오피스 상위 10개 영화[6]를 모아서 분류해 봤습니다. 속편은 색을 칠하고, 원작을 각색한 작품은 빗금으로 칠해서 구분했습니다. 새롭게 만들어 낸 오리지널 영화는 칸을 비웠는데, 결과는 어떨까요? 총 50편 중 오리지널 영화는 단 여섯 편에 불과합니다. 그마저도 〈보헤미안 랩소디〉는 프레디 머큐리의 전기 영화고, 중국의 프로파간다 영화와 중국 전쟁 영화를 제외하면 크리스토퍼 놀란 감독의 〈테넷〉 정도만 남죠. 나머지는 속편 아니면 코믹스 원작을 뒀거나 리메이크 작품입니다.
챗GPT는 세상을 바꿀 파괴적 발견일까?
무엇이든 물어보면 대답해 주는 챗GPT부터 무엇이든 그려 달라고 하면 그려 주는 DALL-E2, 미드저니 같은 인공지능까지. 과거에는 상상하지 못한 일들이 우리 주변에서 바로 이뤄지고 있습니다. 이렇게 고도화된 인공지능은 인류가 생각하지 못한 새로운 아이디어를 뚝딱뚝딱 만들어 내는 혁명적인 기술인 걸까요? 아니면 점점 고도화되는 기술들을 조금 더 다듬은 훌륭한 서비스일까요?
They가 3인칭 단수로 쓰인다고?
반팔티라는 단어, 어떻게 들리나요? 혹시 불편함을 느껴 본 적 있나요? 아마도 없을 겁니다. ‘반팔티’에 특별히 문제가 보이진 않으니까요. 그런데 신체장애를 가진 사람들이 ‘반팔’이라는 단어를 들을 땐 어떨까요. 실제로 장애가 있는 사람들은 반팔티라는 말을 들을 때마다 상처가 된다고 합니다. ‘반팔’ 대신 ‘반소매’라고 표현하는 게 덜 차별적이겠죠.
앉은뱅이책상, 외발 자전거, 결정 장애 등 일상 속 단어 중에 차별적 표현이 담겨 있는 경우가 왕왕 있습니다. 특정 언어를 사용하는 것 자체가 누군가에게 불편함 혹은 상처를 줄 수 있다는 겁니다. 우리가 미처 인지하지 못하고 사용해 왔던 언어에 대해 이야기해 봅니다. 특히 성차별적 언어와 그 차별을 없애기 위해 등장한 성중립 언어에 집중했습니다. 질문을 던집니다. They가 3인칭 단수 대명사로 쓰인다는 사실, 알고 있나요?
성중립 언어란 무엇인가
2018년 유럽의회에서 보고서를 하나 냈습니다. 보고서의 이름은 ‘GENDER NEUTRAL LANGUAGE in the Parliament’. 유럽의회에서 유럽연합 의 법률을 만들거나 서로 의사소통을 할 때 성중립 언어를 사용하자는 취지로 만든 겁니다. 그리고 의원, 직원들에게 배포했습니다. 일종의 가이드북을 만든 거죠. 대표적인 예는 이렇습니다. 과거 EU의 법률에는 인류mankind, 인력manpower과 같은 용어를 표현할 때 남성man의 뜻이 담긴 단어를 썼는데, 앞으로는 성중립적인 용어를 사용하자는 겁니다. 이를테면 인류는 humanity로 인력은 staff로 말이죠. 이처럼 성중립 언어는 성별로 대상을 특정하지 않는 걸 의미합니다.
물론 이 보고서가 법적 구속력이 있거나 무조건 써야 한다는 강제 규정은 아닙니다. 권고 차원에서 만들어진 보고서거든요. 유럽의회가 성중립 언어를 사용해서 좀 더 공정하고 포용적인 의미를 담고, 젠더 고정 관념을 줄여 성평등을 달성해 보자는 차원에서 접근했다고 보면 됩니다. 언어에서 성에 대한 편견과 차별을 걷어 내자는 게 이 보고서의 지향점입니다.
대표적인 성중립 언어가 바로 They입니다. “남자를 지칭할 때는 He를 쓰고, 여자를 지칭할 때는 She를 쓰고, 그리고 여러 사람을 지칭할 때는 They를 쓴다”는 문법이 바뀌고 있습니다. 3인칭 복수 인칭 대명사로 쓰여 온 They가 3인칭 단수 대명사로도 쓰이고 있거든요. 성별을 모르거나 혹은 성별을 알리고 싶지 않은 개인을 가리킬 때 They라고 부르는 식으로 말이죠. 여기에 성별을 규정하지 않는 정체성인 논바이너리를 지칭할 때도 대명사 They를 사용하고 있어요.
사실 성중립 언어에 대한 논의는 꽤 오래됐습니다. 3인칭 단수로 쓰이는 They는 이미 2015년 미국언어연구회에서 올해의 단어로 뽑을 정도니까 말이죠. 《워싱턴 포스트》 역시 2015년부터 They를 단수 대명사로도 활용하고 있기도 합니다. 미국에서 가장 오래된 사전인 메리엄 웹스터 사전에도 이 용례가 올라 있기도 해요. 2019년에는 영국 가수 샘 스미스가 자신의 정체성이 논바이너리라고 커밍아웃하면서 자신을 지칭할 때 언론에서 He나 She 대신 They를 써 달라고 요청한 일도 있었습니다.
성중립으로 변하는 언어들
영어뿐만 아니라 다른 언어를 사용하는 국가에서도 성중립 언어를 사용하려는 모습을 발견할 수 있습니다. 2015년 스웨덴 학술원은 남성과 여성을 가리지 않는 성중립 인칭 대명사를 공식 국어사전에 포함하기도 했습니다. 스웨덴어로 남성을 가리킬 땐 Han을 쓰고, 여성은 Hon을 쓰는데, 성별을 밝히지 않거나 확인되지 않을 때, 혹은 성전환 수술을 한 사람들을 지칭할 때 사용할 대명사로 Hen을 포함한 겁니다.
스웨덴에선 일찍이 1960년대부터 남성 대명사 Han을 포괄적으로 사용하는 것에 대한 비판이 있었습니다. 2010년대 들어서면서 성평등과 성중립을 위한 노력으로 성중립 대명사인 Hen이 일상생활에서 많이 사용되기 시작했습니다. 관공서뿐만 아니라 법원 판결문에도 Hen이 등장했죠. 마지막으로 스웨덴 학술원이 2015년에 공식적으로 인정을 해준 셈입니다.
독일과 프랑스에서도 비슷한 움직임이 있습니다. 그런데 영어와 스웨덴어는 상황이 조금은 다릅니다. 사실 영어, 스웨덴어는 상대적으로 성중립 언어를 적용하는 게 쉽거든요. 왜냐하면 영어와 스웨덴어는 성별이 구분된 단어가 인칭 대명사와 일반 명사 정도로 많지 않습니다. 하지만 독일어과 프랑스어는 문법 안에 성별이 들어 있는지라 상대적으로 고쳐 나가기 힘든 거죠.
예를 들면 이런 식입니다. 프랑스어는 일반적으로 남성형 명사에 e를 붙여서 여성형 명사로 만듭니다. 남성인 친구를 뜻하는 단어는 ami인데, 여성인 친구는 amie 이렇게 쓰는 거죠. 그런데 복수형으로 만들 땐 남성형 명사가 우선되는 법칙이 있습니다.

ⓒ일러스트: 안준석/마부작침
‘친구들’이라는 단어를 표현할 때는 남성형 명사인 ami에 s를 붙여서 amis라고 하는 식으로 말이죠. 독일어도 마찬가지입니다. 남성 친구를 뜻하는 freund에 in이 붙은 freundin이 여성 친구를 뜻하는 단어이고, 친구들은 남성형 명사인 freund에 e를 붙여서 freunde라고 표현합니다.
그러면 이런 단어를 성중립 언어로 표현하려면 어떻게 해야 할까요? 독일어는 크게 네 가지 방법을 활용합니다. 남성형 복수 단어에 여성형 복수 단어를 그냥 병렬적으로 연달아 쓰거나, 혹은 그 사이에 밑줄 문자(_), 별표(*), 슬래시(/) 이런 특수 문자를 쓰는 방법입니다. 프랑스어는 가운뎃점(·)을 표기하는 방식을 주로 활용합니다. 영어와 스웨덴어처럼 단어 하나만 바꾸면 되는 게 아니라 언어 문법 전체가 변해야 하기 때문에 상대적으로 반대하는 사람들의 목소리가 큰 상황입니다.
언어는 생각에 영향을 미친다
성평등을 위해 노력하면 될 일이지 굳이 언어까지 바꿔야 하냐고 생각할 수 있습니다. 언어는 생각을 표현하는 도구 중 하나일 뿐이라고 여길 수도 있죠. UC샌디에이고의 인지 과학자 리라 보로딧츠키 교수는 언어가 인간의 사고방식에 어떤 영향을 미치는지 연구[7]했습니다. 그는 독일어와 스페인어를 구사하는 사람들에게 길을 건너는 다리를 묘사해 달라고 했습니다. 그러자 스페인어 사용자들은 ‘강하다’, ‘길다’와 같이 조금 더 남성적인 표현을 사용해 묘사했습니다. 반면 독일어를 사용자들은 ‘아름답다’, ‘우아하다’는 식의 여성을 표현하는 데 주로 쓰이는 단어를 사용했죠.
왜 이런 차이가 나온 걸까요? 독일어와 마찬가지로 스페인어도 언어 안에 성별이 포함돼 있습니다. 차이는 스페인어로 다리는 남성 명사에 속하고 독일어로 다리는 여성 명사라는 거예요. 즉, 언어의 성별에 따라 사물에 대한 인식 차이가 날 수 있다는 겁니다. 언어가 단순히 표현하는 도구일 뿐만 아니라 언어를 사용하는 사람들의 생각에도 영향을 미칠 수있다는 거죠.
그러면 이런 단어를 성중립 언어로 표현하려면 어떻게 해야 할까요? 독일어는 크게 네 가지 방법을 활용합니다. 남성형 복수 단어에 여성형 복수 단어를 그냥 병렬적으로 연달아 쓰거나, 혹은 그 사이에 밑줄 문자(_), 별표(*), 슬래시(/) 이런 특수 문자를 쓰는 방법입니다. 프랑스어는 가운뎃점(·)을 표기하는 방식을 주로 활용합니다. 영어와 스웨덴어처럼 단어 하나만 바꾸면 되는 게 아니라 언어 문법 전체가 변해야 하기 때문에 상대적으로 반대하는 사람들의 목소리가 큰 상황입니다.
언어는 생각에 영향을 미친다
성평등을 위해 노력하면 될 일이지 굳이 언어까지 바꿔야 하냐고 생각할 수 있습니다. 언어는 생각을 표현하는 도구 중 하나일 뿐이라고 여길 수도 있죠. UC샌디에이고의 인지 과학자 리라 보로딧츠키 교수는 언어가 인간의 사고방식에 어떤 영향을 미치는지 연구[7]했습니다. 그는 독일어와 스페인어를 구사하는 사람들에게 길을 건너는 다리를 묘사해 달라고 했습니다. 그러자 스페인어 사용자들은 ‘강하다’, ‘길다’와 같이 조금 더 남성적인 표현을 사용해 묘사했습니다. 반면 독일어를 사용자들은 ‘아름답다’, ‘우아하다’는 식의 여성을 표현하는 데 주로 쓰이는 단어를 사용했죠.
왜 이런 차이가 나온 걸까요? 독일어와 마찬가지로 스페인어도 언어 안에 성별이 포함돼 있습니다. 차이는 스페인어로 다리는 남성 명사에 속하고 독일어로 다리는 여성 명사라는 거예요. 즉, 언어의 성별에 따라 사물에 대한 인식 차이가 날 수 있다는 겁니다. 언어가 단순히 표현하는 도구일 뿐만 아니라 언어를 사용하는 사람들의 생각에도 영향을 미칠 수있다는 거죠.

ⓒ일러스트: 안준석/마부작침
성차별적 언어를 사용하는 사람들이 실제 성차별적인 인식을 가지는지, 그 영향을 분석한 자료를 봅니다. 2020년 네이처에 올라온 논문[8]인데, 39개국의 65만 7335명의 데이터를 가지고 성별 연관성을 조사한 자료입니다. 여기에 활용한 데이터는 크게 두 가지입니다. 우선 첫 번째는 각 언어별로 성 고정 관념이 어느 정도인지 수치화한 데이터입니다. 두 번째는 각 언어를 사용하는 개인의 성 고정 관념을 정량화한 데이터죠.
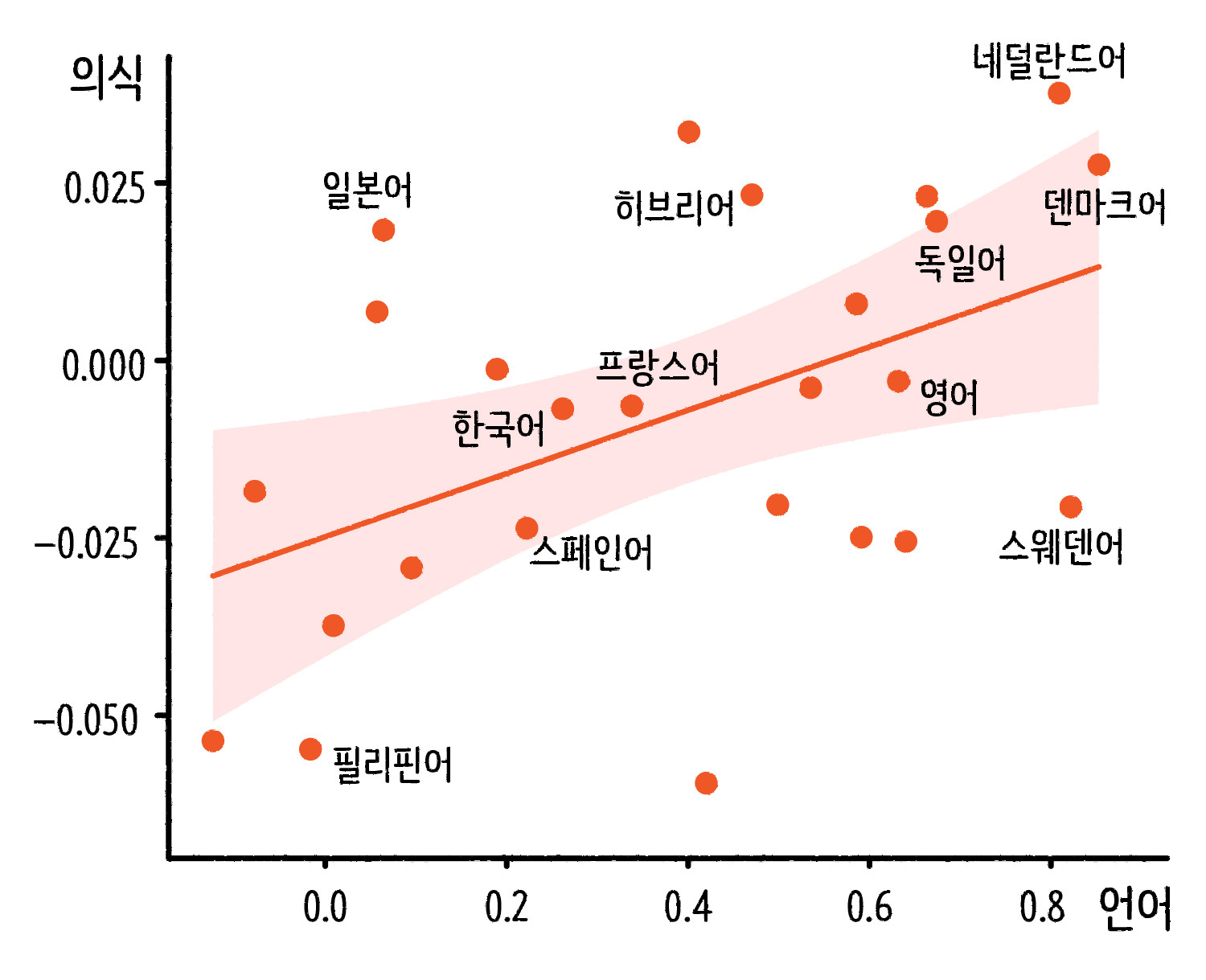
성차별적 언어가 성차별적 인식에 미치는 영향 ⓒ일러스트: 안준석/마부작침
언어 속 성 고정 관념을 측정하기 위해 총 25개의 언어를 가지고 남성Male과 여성Female이 각각 가정Family과 직업Career 중에 어떤 단어와 연관성이 더 높게 나오는지 분석했습니다. 남성-직업, 여성-가정의 연관성이 더 크면 성 고정 관념이 강한 언어로 보는 것이죠. 여기에 개인의 문화적 고정 관념을 파악하는 데 주로 사용하는 내재적 연관 검사 IAT 데이터와의 관계까지 살펴봤습니다. 위의 그래프에서 알 수 있듯 두 데이터는 양(+)의 상관관계가 있었습니다. 성 고정 관념이 강한 언어를 사용하는 사람 개개인의 성 고정 관념이 더 강했다는 거죠.
유모차를 유아차로
우리나라의 성차별 언어는 얼마나 될까요? 한국어는 독일어와 프랑스어처럼 성별이 박혀 있는 언어보다 상대적으로 성중립적이기 쉬운 언어 구조를 가지고 있습니다. 하지만 그럼에도 불구하고 한국어 곳곳에서 성차별적 언어를 어렵지 않게 발견할 수 있습니다. 2018년 여성가족부가 조사한 ‘일상 속 성차별 언어 표현 현황 연구’[9] 결과를 보면, 성차별 언어 표현을 한 번이라도 접해 본 사람의 비율은 응답자의 90퍼센트를 넘었습니다. 특히 성 역할에 관한 차별 표현이 91.1퍼센트로 가장 많았어요. 여성을 지칭할 때만 ‘여’ 자를 따로 붙이는 ‘여배우’, ‘여의사’, ‘여경’ 같은 단어들이 그런 예가 되겠죠.
가족 호칭에서도 남편 쪽의 친척에게는 ‘도련님’, ‘아가씨’로 높여 부르지만 아내 쪽은 ‘처남’, ‘처제’로 부르고 있습니다. 남성과 여성을 병렬적으로 배치할 경우에 ‘남녀노소’, ‘아들딸’, ‘남녀 공학’ 등 남성이 먼저 위치하지만 비하하는 표현을 사용할 땐 ‘연놈’과 같이 여성을 지칭하는 말이 먼저 오기도 하고요. 여성이 앞에 와 있는 ‘Ladies and Gentlemen’을 ‘신사 숙녀 여러분’으로 뒤바꿔 번역하기도 하죠.
이러한 성차별적 표현을 바꾸기 위한 노력은 곳곳에서 보입니다. 앞에 정리해 둔 건 서울시 여성가족재단에서 2018년부터 진행하고 있는 성평등 언어 사전의 일부 내용입니다. 서울시는 시민들과 함께 성중립 언어 개선안을 만들어 공표하고 있습니다. 국립국어원은 가족 호칭에 대해 아내 쪽 친척을 남편 쪽 친척의 호칭처럼 ‘님’을 붙여 부르는 방식을 권고했습니다.
가장 보수적인 언어가 통용되는 법령 용어도 성차별적 언어 표현이 성중립 언어로 대체되고 있습니다. 법 조문에는 여전히 ‘미망인’과 같이 성차별적 표현이 있거든요. 이를 바꿔 보려고 한국법제연구원이 법률을 전수 조사해서 차별 언어를 검토했습니다. 2022년 3월, 법무부 디지털 성범죄 전문위원회는 ‘성적 수치심’이라는 단어를 성중립적 용어로 변경하라고 권고하기도 했습니다.
우리나라 성평등은 어디쯤?
스포츠 용어, 법적 용어, 그리고 우리 일상생활 용어 곳곳에 여전히 성차별 표현이 남아 있습니다. 사회 곳곳에 묻어 있는 성차별 표현은 우리 사회의 성차별적 구조가 남긴 흔적이라고 볼 수 있을지 모릅니다. 우리나라의 성평등 수준은 어디까지 와 있는지 한 번 짚어 볼 필요가 있습니다. 관련 지표 두 개를 분석했습니다. 하나는 UN 산하 기관 유엔개발계획UNDP에서 제공하는 성불평등 지수(GII·Gender Inequality Index)이고, 또 하나는 세계경제포럼WEF에서 발표하는 성격차 지수(GGI·Gender Gap Index)입니다.
두 지표는 약간 다른데, 우선 GII는 여성이 어떤 수준의 삶을 살고 있는지를 판단한 절대 평가 점수라고 할 수 있습니다. 반면 GGI는 남성과 여성 사이의 차이를 가지고 만든 상대 평가 점수죠. 또 활용하는 데이터도 차이가 있어요. GGI에는 사회 경제적 지표가 포함돼 있습니다. 사회 경제 분야에서 남성과 여성의 지위를 비교할 수 있는 직업 내 성비, 임금 격차, 여성 장관 수 등의 수치가 GGI에는 한 축으로 자리 잡고 있습니다. 반면, GII에는 포함돼 있지 않아요. GII에는 건강과 교육 데이터가 중심입니다. 모성사망비와 청소년 출산율처럼 조금 더 직접적으로 여성의 삶의 질을 파악할 수 있는 데이터를 포함한 거죠.
유모차를 유아차로
우리나라의 성차별 언어는 얼마나 될까요? 한국어는 독일어와 프랑스어처럼 성별이 박혀 있는 언어보다 상대적으로 성중립적이기 쉬운 언어 구조를 가지고 있습니다. 하지만 그럼에도 불구하고 한국어 곳곳에서 성차별적 언어를 어렵지 않게 발견할 수 있습니다. 2018년 여성가족부가 조사한 ‘일상 속 성차별 언어 표현 현황 연구’[9] 결과를 보면, 성차별 언어 표현을 한 번이라도 접해 본 사람의 비율은 응답자의 90퍼센트를 넘었습니다. 특히 성 역할에 관한 차별 표현이 91.1퍼센트로 가장 많았어요. 여성을 지칭할 때만 ‘여’ 자를 따로 붙이는 ‘여배우’, ‘여의사’, ‘여경’ 같은 단어들이 그런 예가 되겠죠.
가족 호칭에서도 남편 쪽의 친척에게는 ‘도련님’, ‘아가씨’로 높여 부르지만 아내 쪽은 ‘처남’, ‘처제’로 부르고 있습니다. 남성과 여성을 병렬적으로 배치할 경우에 ‘남녀노소’, ‘아들딸’, ‘남녀 공학’ 등 남성이 먼저 위치하지만 비하하는 표현을 사용할 땐 ‘연놈’과 같이 여성을 지칭하는 말이 먼저 오기도 하고요. 여성이 앞에 와 있는 ‘Ladies and Gentlemen’을 ‘신사 숙녀 여러분’으로 뒤바꿔 번역하기도 하죠.
- 유모차 → 유아차 ; 여성(母)만 포함된 단어로 평등 육아 개념과 맞지 않습니다. 아이가 중심이 되는 유아차가 성중립 언어라고 할 수 있습니다.
- 스포츠맨십 → 스포츠 정신 ; 스포츠를 하는 누구나 가져야 하는 스포츠 정신에 남성(man)만 포함된 단어는 성평등에 어긋납니다.
- 자매결연 → 상호결연 ; 상호 간의 관계 형성의 사회적 의미를 ‘자매’라는 여성적 관계로 표현해 여성에 대한 인격적 편향성을 높일 수 있다는 점에서 차별적 표현입니다.
이러한 성차별적 표현을 바꾸기 위한 노력은 곳곳에서 보입니다. 앞에 정리해 둔 건 서울시 여성가족재단에서 2018년부터 진행하고 있는 성평등 언어 사전의 일부 내용입니다. 서울시는 시민들과 함께 성중립 언어 개선안을 만들어 공표하고 있습니다. 국립국어원은 가족 호칭에 대해 아내 쪽 친척을 남편 쪽 친척의 호칭처럼 ‘님’을 붙여 부르는 방식을 권고했습니다.
가장 보수적인 언어가 통용되는 법령 용어도 성차별적 언어 표현이 성중립 언어로 대체되고 있습니다. 법 조문에는 여전히 ‘미망인’과 같이 성차별적 표현이 있거든요. 이를 바꿔 보려고 한국법제연구원이 법률을 전수 조사해서 차별 언어를 검토했습니다. 2022년 3월, 법무부 디지털 성범죄 전문위원회는 ‘성적 수치심’이라는 단어를 성중립적 용어로 변경하라고 권고하기도 했습니다.
우리나라 성평등은 어디쯤?
스포츠 용어, 법적 용어, 그리고 우리 일상생활 용어 곳곳에 여전히 성차별 표현이 남아 있습니다. 사회 곳곳에 묻어 있는 성차별 표현은 우리 사회의 성차별적 구조가 남긴 흔적이라고 볼 수 있을지 모릅니다. 우리나라의 성평등 수준은 어디까지 와 있는지 한 번 짚어 볼 필요가 있습니다. 관련 지표 두 개를 분석했습니다. 하나는 UN 산하 기관 유엔개발계획UNDP에서 제공하는 성불평등 지수(GII·Gender Inequality Index)이고, 또 하나는 세계경제포럼WEF에서 발표하는 성격차 지수(GGI·Gender Gap Index)입니다.
두 지표는 약간 다른데, 우선 GII는 여성이 어떤 수준의 삶을 살고 있는지를 판단한 절대 평가 점수라고 할 수 있습니다. 반면 GGI는 남성과 여성 사이의 차이를 가지고 만든 상대 평가 점수죠. 또 활용하는 데이터도 차이가 있어요. GGI에는 사회 경제적 지표가 포함돼 있습니다. 사회 경제 분야에서 남성과 여성의 지위를 비교할 수 있는 직업 내 성비, 임금 격차, 여성 장관 수 등의 수치가 GGI에는 한 축으로 자리 잡고 있습니다. 반면, GII에는 포함돼 있지 않아요. GII에는 건강과 교육 데이터가 중심입니다. 모성사망비와 청소년 출산율처럼 조금 더 직접적으로 여성의 삶의 질을 파악할 수 있는 데이터를 포함한 거죠.
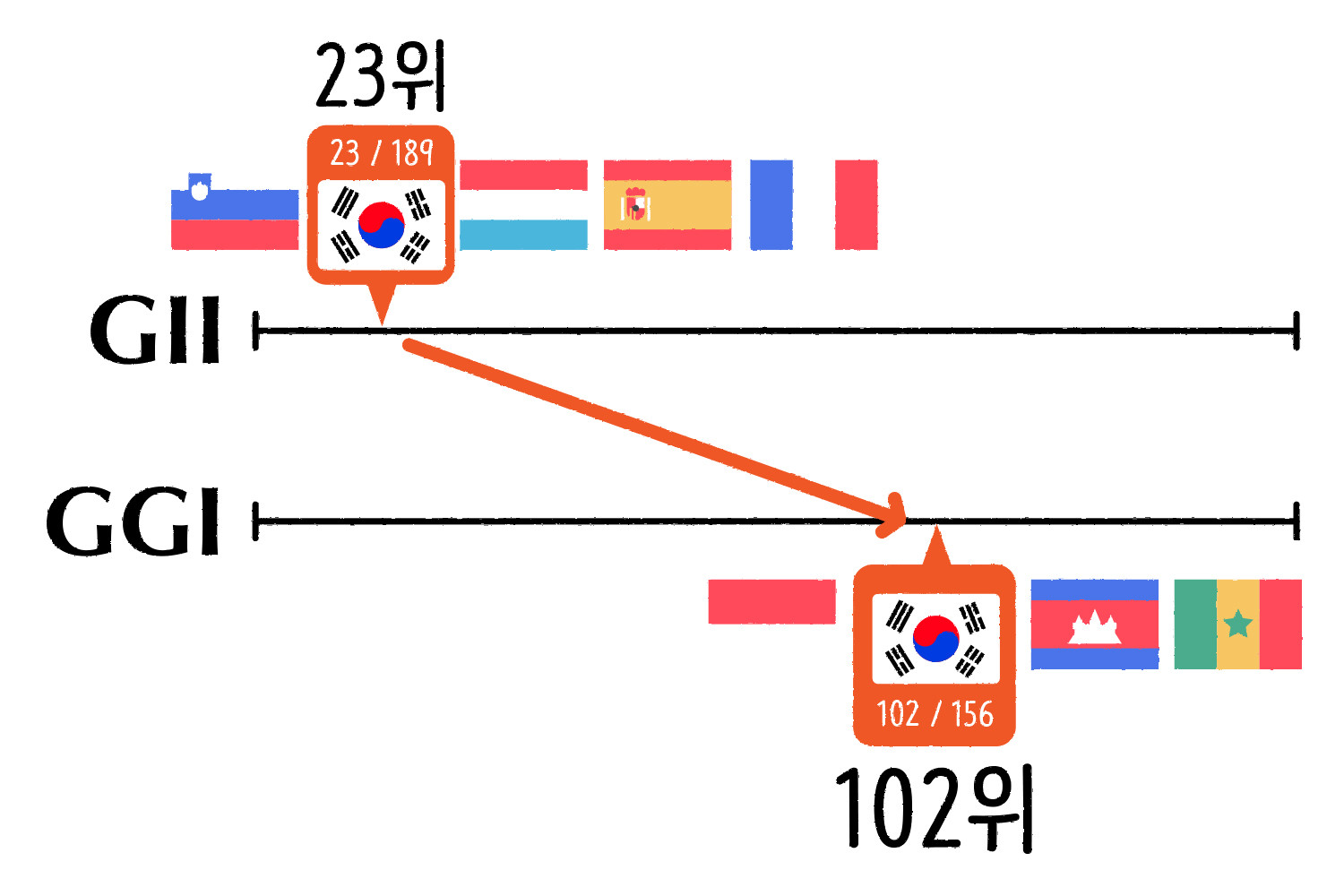
대한민국 성평등 지수 ⓒ일러스트: 안준석/마부작침
2020년 기준으로 우리나라의 GII 순위는 전 세계 189개국 중 23위입니다. 아시아 국가 중 일본에 이은 2위를 기록할 정도로 높은 수치죠. 반면 GGI는 2021년 기준으로 156개국 중 102위로 하위권입니다. 인도네시아, 캄보디아, 세네갈과 비슷한 수준입니다. GII와 동일한 시점으로 비교하면 2020년엔 153개국 중 108위로 더 순위가 낮습니다. 한마디로 정리하면, 여성 삶의 수준 (GII)은 선진국 수준으로 올라왔지만 성별 간 격차(GGI)는 여전히 전 세계 하위권이라고 할 수 있습니다.
2021년 양성평등 실태 조사[10]에서도 여전히 우리 사회가 불평등하다는 인식이 많이 남아 있습니다. 여성의 65.4퍼센트, 그리고 남성의 41.4퍼센트가 우리 사회가 전반적으로 여성에게 불평등하다고 답변할 정도거든요. 특히 20대와 30대 여성은 70퍼센트가 넘는 비율로 여성이 불평등한 사회를 살고 있다고 답변했습니다.
성중립 언어, 필요할까?
성중립 언어가 성차별을 막는 역할을 할 수 있을까요? 적극적으로 성중립 언어를 만들고 사용하는 해외에서도 적지 않은 갈등이 벌어지고 있습니다. 프랑스에선 성중립 대명사 iel이 프랑스어 사전에 추가된다고 하자 엄청난 논쟁이 벌어지기도 했죠. 실제로 사용하고 있는 만큼 그 흐름을 반영해서 사전에 추가해야 한다는 입장과 언어 문법에 혼란을 가져올 것이라며 반대하는 입장이 팽팽히 맞섰습니다.
독일도 비슷합니다. 이미 성중립 언어를 사용하는 사람들이 있지만 2021년 여론 조사 결과를 보면 응답자의 65퍼센트가 성중립 표현은 너무 길고 불편하다는 이유로 부정적인 의견을 내고 있거든요. 새롭게 만들어지는 언어를 다 받아 주면 기존 문법 체계가 붕괴할 수 있다고 우려하는 사람도 많습니다. 차별적 표현을 막기 위해 성중립 언어를 적극적으로 사용하는 게 맞을까요? 아니면 언어까지 고치는 건 불필요한 사회적 비용을 초래하는 일인 걸까요?
2021년 양성평등 실태 조사[10]에서도 여전히 우리 사회가 불평등하다는 인식이 많이 남아 있습니다. 여성의 65.4퍼센트, 그리고 남성의 41.4퍼센트가 우리 사회가 전반적으로 여성에게 불평등하다고 답변할 정도거든요. 특히 20대와 30대 여성은 70퍼센트가 넘는 비율로 여성이 불평등한 사회를 살고 있다고 답변했습니다.
성중립 언어, 필요할까?
성중립 언어가 성차별을 막는 역할을 할 수 있을까요? 적극적으로 성중립 언어를 만들고 사용하는 해외에서도 적지 않은 갈등이 벌어지고 있습니다. 프랑스에선 성중립 대명사 iel이 프랑스어 사전에 추가된다고 하자 엄청난 논쟁이 벌어지기도 했죠. 실제로 사용하고 있는 만큼 그 흐름을 반영해서 사전에 추가해야 한다는 입장과 언어 문법에 혼란을 가져올 것이라며 반대하는 입장이 팽팽히 맞섰습니다.
독일도 비슷합니다. 이미 성중립 언어를 사용하는 사람들이 있지만 2021년 여론 조사 결과를 보면 응답자의 65퍼센트가 성중립 표현은 너무 길고 불편하다는 이유로 부정적인 의견을 내고 있거든요. 새롭게 만들어지는 언어를 다 받아 주면 기존 문법 체계가 붕괴할 수 있다고 우려하는 사람도 많습니다. 차별적 표현을 막기 위해 성중립 언어를 적극적으로 사용하는 게 맞을까요? 아니면 언어까지 고치는 건 불필요한 사회적 비용을 초래하는 일인 걸까요?
[1]
한국은행, 〈최근 현금없는 사회 진전 국가들의 주요 이슈와 시사점〉, 2020.
[2]
한국은행, 〈2019년 지급수단 및 모바일금융서비스 이용행태 조사결과〉, 2020.
[3]
BIS Statistics에서 제공하는 ‘Use of payment services/instruments: volume of cashless payments’ 데이터를 활용했습니다.
[4]
다중코어 아키텍처, 반도체 장치 시뮬레이션을 연구하는 전산과학자 karl rupp의 데이터 입니다. 그 중 트랜지스터 데이터만 활용해 시각화했습니다.
[5]
Michael Park, Erin Leahey and Russell J. Funk, 〈Papers and patents are becoming less disruptive over time〉, 《Nature》 613, 2023, pp138-144.
[6]
Numbers, 〈All Time Worldwide Box Office〉, 2019-2022.
[7]
TED, 〈How language shapes the way we think | Lera Boroditsky〉, 2018.5.2.
[8]
Molly Lewis and Gary Lupyan , 〈Gender stereotypes are reflected in the distributional structure of 25 languages〉, 《Nature Human Behaviour》 4, 2020, pp1021-1028.
[9]
한국여성정책연구원, 〈일상 속 성차별 언어표현 현황 연구〉, 2019.
[10]
여성가족부, 〈성평등 체감도 상승했으나 일터와 돌봄의 성별 불균형, 여성폭력 현실에 높은 문제의식〉, 2022.4.19.